චි-චතුරස්ර බෙදා හැරීම. MS EXCEL හි ගණිතමය සංඛ්යාලේඛන බෙදා හැරීම. සංඛ්යාත බෙදාහැරීම් දෙකක සංසන්දනය. චි-චතුරස්ර පරීක්ෂණය
Chi-square බෙදා හැරීම සලකා බලන්න. MS EXCEL ශ්රිතය භාවිතා කිරීමCH2.DIST() අපි බෙදාහැරීමේ ශ්රිතය සහ සම්භාවිතා ඝනත්වය සැලසුම් කරමු, සහ ගණිතමය සංඛ්යාලේඛන අරමුණු සඳහා මෙම ව්යාප්තිය භාවිතා කිරීම පැහැදිලි කරමු.
Chi-square බෙදා හැරීම (X 2, XI2,ඉංග්රීසිචි- වර්ග කර ඇතබෙදා හැරීම) භාවිතා කරන ලදී විවිධ ක්රමගණිතමය සංඛ්යාලේඛන:
- ඉදිකිරීම් අතරතුර;
- හිදී ;
- at (සෛද්ධාන්තික බෙදා හැරීමේ ශ්රිතය පිළිබඳ අපගේ උපකල්පනයට අනුභූතික දත්ත එකඟද නැද්ද යන්න, ඉංග්රීසි Goodness-of-fit)
- at (වර්ග විචල්ය දෙකක් අතර සම්බන්ධතාවය තීරණය කිරීමට භාවිතා කරයි, ඉංග්රීසි චි-චතුරශ්රය ඇසුරේ පරීක්ෂණය).
අර්ථ දැක්වීම: x 1 , x 2 , ..., x n යනු N(0;1) හරහා බෙදා හරින ලද ස්වාධීන අහඹු විචල්යයන් නම්, Y=x 1 2 + x 2 2 +...+ x n 2 හි සසම්භාවී විචල්යයේ ව්යාප්තිය ඇත. බෙදා හැරීම X 2 නිදහසේ අංශක n සමඟ.
බෙදා හැරීම X 2 යනුවෙන් හැඳින්වෙන එක් පරාමිතියක් මත රඳා පවතී නිදහසේ උපාධි (ඩී එෆ්, උපාධිවලනිදහස) උදාහරණයක් ලෙස, ගොඩනඟන විට නිදහසේ අංශක ගණන df=n-1 සමාන වේ, මෙහි n යනු විශාලත්වය වේ සාම්පල.
බෙදා හැරීමේ ඝනත්වය X 2
සූත්රය මගින් ප්රකාශිත:
කාර්ය ප්රස්ථාර
බෙදා හැරීම X 2 අසමමිතික හැඩයක් ඇත, n ට සමාන, 2n ට සමාන වේ.
තුල ප්රස්තාර පත්රයේ උදාහරණ ගොනුවලබා දී ඇත බෙදාහැරීමේ ඝනත්ව ප්රස්තාරසම්භාවිතා සහ සමුච්චිත බෙදාහැරීමේ කාර්යය.
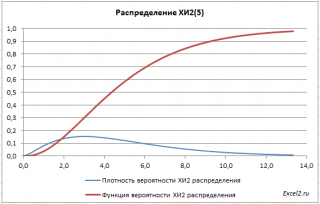
ප්රයෝජනවත් දේපල CH2 බෙදාහැරීම්
x 1 , x 2 , ..., x n ස්වාධීන අහඹු විචල්ය බෙදා හරිනු ලැබේවා සාමාන්ය නීතියඑම පරාමිති μ සහ σ සමග, සහ X avවේ අංක ගණිත මධ්යන්යයමෙම x අගයන්.
ඉන්පසු අහඹු අගය yසමාන

එයට තිබෙනවා X 2 - බෙදා හැරීමනිදහසේ n-1 අංශක සමඟ. නිර්වචනය භාවිතා කරමින්, ඉහත ප්රකාශනය පහත පරිදි නැවත ලිවිය හැකිය:

එබැවින්, නියැදි බෙදා හැරීමසංඛ්යාලේඛන y, at නියැදියසිට සාමාන්ය බෙදාහැරීමේ , එයට තිබෙනවා X 2 - බෙදා හැරීමනිදහසේ n-1 අංශක සමඟ.
අපට මෙම දේපල අවශ්ය වන්නේ කවදාද යන්නයි. නිසා විසුරුමසමහර විට නිකම් ධනාත්මක අංකය, ඒ X 2 - බෙදා හැරීමඑවිට එය ඇගයීමට භාවිතා කරයි y d.b >0, අර්ථ දැක්වීමේ දක්වා ඇති පරිදි.
MS EXCEL හි CH2 බෙදා හැරීම
MS EXCEL හි, 2010 අනුවාදයේ සිට, සඳහා X 2 -බෙදාහැරීම්විශේෂ කාර්යයක් ඇත CHI2.DIST(), ඉංග්රීසි නම– CHISQ.DIST(), ඔබට ගණනය කිරීමට ඉඩ සලසයි සම්භාවිතා ඝනත්වය(ඉහත සූත්රය බලන්න) සහ (අහඹු විචල්ය X සතුව ඇති සම්භාවිතාව CI2-බෙදා හැරීම, x, P(X) ට වඩා අඩු හෝ සමාන අගයක් ගනී<= x}).
සටහන: නිසා CH2 බෙදා හැරීමයනු විශේෂ අවස්ථාවක්, පසුව සූත්රය =GAMMA.DIST(x;n/2;2;TRUE)ධන නිඛිල සඳහා n සූත්රයේ ප්රතිඵලයම ලබා දෙයි =CHI2.DIST(x;n; TRUE)හෝ =1-CHI2.DIST.PH(x;n) . සහ සූත්රය =GAMMA.DIST(x;n/2;2;FALSE)සූත්රය හා සමාන ප්රතිඵලය ලබා දෙයි =CHI2.DIST(x;n; FALSE), i.e. සම්භාවිතා ඝනත්වය CH2 බෙදාහැරීම්.
HI2.DIST.PH() ශ්රිතය නැවත පැමිණේ බෙදා හැරීමේ කාර්යය, වඩාත් නිවැරදිව, දකුණු පැත්තේ සම්භාවිතාව, i.e. P(X > x). සමානාත්මතාවය සත්ය බව පැහැදිලිය
=CHI2.DIST.PH(x;n)+CHI2.DIST(x;n;TRUE)=1
නිසා පළමු වාරය P(X > x) සම්භාවිතාව ගණනය කරයි, සහ දෙවන P(X<= x}.
MS EXCEL 2010 ට පෙර, EXCEL සතුව තිබුණේ CHIDIST() ශ්රිතය පමණි, එය ඔබට දකුණු පැත්තේ සම්භාවිතාව ගණනය කිරීමට ඉඩ සලසයි, i.e. P(X > x). නව MS EXCEL 2010 ශ්රිතවල ඇති හැකියාවන් XI2.DIST() සහ XI2.DIST.PH() මෙම ශ්රිතයේ හැකියාවන් ආවරණය කරයි. CH2DIST() ශ්රිතය ගැළපීම සඳහා MS EXCEL 2010 හි ඉතිරි වේ.
CHI2.DIST() නැවත ලබා දෙන එකම ශ්රිතයයි chi2 ව්යාප්තියේ සම්භාවිතා ඝනත්වය(තෙවන තර්කය අසත්ය විය යුතුය). ඉතිරි කාර්යයන් නැවත පැමිණේ සමුච්චිත බෙදාහැරීමේ කාර්යය, i.e. සසම්භාවී විචල්යය නිශ්චිත පරාසයෙන් අගයක් ගන්නා සම්භාවිතාව: P(X<= x}.
ඉහත MS EXCEL කාර්යයන් ලබා දී ඇත.
උදාහරණ
සසම්භාවී විචල්යය X ලබා දී ඇති අගයට වඩා අඩු හෝ සමාන අගයක් ගැනීමේ සම්භාවිතාව සොයා ගනිමු x: පී(X<= x}. Это можно сделать несколькими функциями:
CHI2.DIST(x; n; TRUE)
=1-HI2.DIST.PH(x; n)
=1-CHI2DIST(x; n)
CH2.DIST.PH() ශ්රිතය P(X) සොයා ගැනීමට ඊනියා දකුණු පස සම්භාවිතාව P(X > x) සම්භාවිතාව ලබා දෙයි.<= x}, необходимо вычесть ее результат от 1.
සසම්භාවී විචල්ය X ලබා දී ඇති අගයකට වඩා වැඩි අගයක් ගැනීමේ සම්භාවිතාව සොයා ගනිමු x: P(X > x). මෙය කාර්යයන් කිහිපයක් සමඟ කළ හැකිය:
1-CHI2.DIST(x; n; TRUE)
=HI2.DIST.PH(x; n)
=CHI2DIST(x; n)
ප්රතිලෝම chi2 බෙදා හැරීමේ ශ්රිතය
ගණනය කිරීම සඳහා ප්රතිලෝම ශ්රිතය භාවිතා වේ ඇල්ෆා-, i.e. අගයන් ගණනය කිරීමට xදී ඇති සම්භාවිතාව සඳහා ඇල්ෆා, සහ x P(X) ප්රකාශනය තෘප්තිමත් කළ යුතුය<= x}=ඇල්ෆා.
CH2.INV() ශ්රිතය ගණනය කිරීමට භාවිතා කරයි සාමාන්ය ව්යාප්තියේ විචලනයේ විශ්වාස කාලාන්තර.
CHI2.OBR.PH() ශ්රිතය ගණනය කිරීමට භාවිතා කරයි, i.e. වැදගත්කම මට්ටමක් ශ්රිතයට තර්කයක් ලෙස දක්වා තිබේ නම්, උදාහරණයක් ලෙස 0.05, එවිට ශ්රිතය අහඹු විචල්ය x හි අගයක් ආපසු ලබා දෙනු ඇත, ඒ සඳහා P(X>x)=0.05. සංසන්දනය කිරීමක් ලෙස: XI2.INR() ශ්රිතය P(X සඳහා වන අහඹු විචල්ය x හි අගයක් ලබා දෙනු ඇත.<=x}=0,05.
MS EXCEL 2007 සහ ඊට පෙර, HI2.OBR.PH( වෙනුවට, HI2OBR() ශ්රිතය භාවිතා කරන ලදී.
ඉහත කාර්යයන් එකිනෙකට හුවමාරු කළ හැක, මන්ද පහත සූත්ර එකම ප්රතිඵලය ලබා දෙයි:
=CHI.OBR(alpha;n)
=HI2.OBR.PH(1-alpha;n)
=CHI2INV(1- ඇල්ෆා;n)
ගණනය කිරීම් සඳහා උදාහරණ කිහිපයක් දක්වා ඇත Functions පත්රයේ උදාහරණ ගොනුව.
MS EXCEL ක්රියා කරන්නේ CH2 බෙදාහැරීම භාවිතා කරමිනි
පහත දැක්වෙන්නේ රුසියානු සහ ඉංග්රීසි ශ්රිත නාම අතර ලිපි හුවමාරුවයි.
CH2.DIST.PH() - ඉංග්රීසි. නම CHISQ.DIST.RT, i.e. CHI-චතුරශ්රය බෙදාහැරීම දකුණු වලිගය, දකුණු වලිග චි-චතුරශ්රය(d) බෙදා හැරීම
CH2.OBR() - ඉංග්රීසි. නම CHISQ.INV, i.e. CHI-වර්ග බෙදාහැරීම INVerse
CH2.PH.OBR() - ඉංග්රීසි. නම CHISQ.INV.RT, i.e. CHI-වර්ග බෙදාහැරීම INVerse Right Tail
CH2DIST() - ඉංග්රීසි. නම CHIDIST, CHISQ.DIST.RT ට සමාන ශ්රිතය
CH2OBR() - ඉංග්රීසි. නම CHIINV, i.e. CHI-වර්ග බෙදාහැරීම INVerse
බෙදා හැරීමේ පරාමිතීන් ඇස්තමේන්තු කිරීම
නිසා සාමාන්යයෙන් CH2 බෙදා හැරීමගණිතමය සංඛ්යාලේඛන අරමුණු සඳහා භාවිතා කරයි (ගණනය කිරීම විශ්වාස කාලාන්තර, පරීක්ෂණ උපකල්පන ආදිය)සහ සැබෑ අගයන් ආකෘති තැනීම සඳහා කිසි විටෙකත් පාහේ, මෙම බෙදාහැරීම සඳහා බෙදාහැරීමේ පරාමිතීන් තක්සේරු කිරීම පිළිබඳ සාකච්ඡාව මෙහි සිදු නොකෙරේ.
සාමාන්ය ව්යාප්තිය මගින් CI2 ව්යාප්තිය ආසන්න කිරීම
නිදහසේ අංශක ගණන n>30 සමඟ බෙදා හැරීම X 2හොඳින් ආසන්න සාමාන්ය බෙදාහැරීමේසමග සාමාන්ය අගයμ=n සහ විචලනය σ=2*n (බලන්න උදාහරණ පත්ර ගොනුව ආසන්න කිරීම).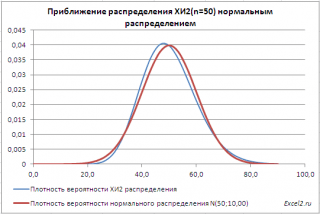
) පරීක්ෂා කෙරෙන කල්පිතයේ නිශ්චිත සූත්රගත කිරීම එක් එක් අවස්ථාවට වෙනස් වේ.
ප්රතිශක්ති විද්යාවෙන් (උපකල්පිත) උදාහරණයක් භාවිතා කරමින් \(\chi^2\) නිර්ණායකය ක්රියා කරන ආකාරය මෙම පෝස්ටුවෙන් විස්තර කරමි. සුදුසු ප්රතිදේහ ශරීරයට හඳුන්වා දුන් විට ක්ෂුද්රජීවී රෝගයක් වර්ධනය වීම මර්දනය කිරීමේ කාර්යක්ෂමතාවය තීරණය කිරීම සඳහා අපි අත්හදා බැලීමක් සිදු කර ඇති බව සිතමු. මෙම අත්හදා බැලීම සඳහා මීයන් 111 ක් සම්බන්ධ වූ අතර, අපි පිළිවෙලින් සතුන් 57 සහ 54 ඇතුළුව කණ්ඩායම් දෙකකට බෙදා ඇත. මීයන් පළමු කණ්ඩායම ව්යාධිජනක බැක්ටීරියා එන්නත් ලබා, පසුව මෙම බැක්ටීරියා වලට එරෙහිව ප්රතිදේහ අඩංගු රුධිර සෙරුමය හඳුන්වා දීම. දෙවන කණ්ඩායමේ සතුන් පාලනයන් ලෙස සේවය කළහ - ඔවුන්ට ලැබුණේ බැක්ටීරියා එන්නත් පමණි. ටික වේලාවකට පසු, මීයන් 38 ක් මිය ගොස් 73 ක් දිවි ගලවා ගත් බව පෙනී ගියේය. මියගිය අයගෙන් 13 ක් පළමු කණ්ඩායමට අයත් වන අතර 25 ක් දෙවන කණ්ඩායමට (පාලනය) අයත් වේ. මෙම අත්හදා බැලීමේදී පරීක්ෂා කරන ලද ශුන්ය උපකල්පනය පහත පරිදි සකස් කළ හැකිය: ප්රතිදේහ සහිත සෙරුමය පරිපාලනය මීයන්ගේ පැවැත්මට බලපෑමක් නැත. වෙනත් වචන වලින් කිවහොත්, අපි තර්ක කරන්නේ මූසිකයේ පැවැත්මේ නිරීක්ෂිත වෙනස්කම් (පළමු කණ්ඩායමේ 77.2% සහ දෙවන කණ්ඩායමේ 53.7%) සම්පූර්ණයෙන්ම අහඹු වන අතර ඒවා ප්රතිදේහවල බලපෑමට සම්බන්ධ නොවේ.
පරීක්ෂණයෙන් ලබාගත් දත්ත වගුවක ස්වරූපයෙන් ඉදිරිපත් කළ හැකිය:
මුළු |
|||
බැක්ටීරියා + සෙරුමය |
|||
බැක්ටීරියා පමණි |
|||
මුළු |
පෙන්වා ඇති වගු වැනි වගු හඳුන්වන්නේ හදිසි අවස්ථා වගු ලෙසිනි. සලකා බලනු ලබන උදාහරණයේ දී, වගුවේ මානය 2x2 වේ: වස්තු කාණ්ඩ දෙකක් ඇත ("බැක්ටීරියා + සෙරුමය" සහ "බැක්ටීරියා පමණි"), ඒවා නිර්ණායක දෙකක් ("මියගිය" සහ "ගැළවී ගිය") අනුව පරීක්ෂා කරනු ලැබේ. හදිසි අවස්ථා වගුවක සරලම අවස්ථාව මෙයයි: ඇත්ත වශයෙන්ම, අධ්යයනය කරන පන්ති ගණන සහ විශේෂාංග ගණන යන දෙකම වැඩි විය හැක.
ඉහත සඳහන් කර ඇති ශුන්ය උපකල්පනය පරීක්ෂා කිරීම සඳහා, ප්රතිදේහ ඇත්ත වශයෙන්ම මීයන්ගේ පැවැත්මට කිසිදු බලපෑමක් නොකළහොත් තත්වය කුමක් වේද යන්න අප දැනගත යුතුය. වෙනත් වචන වලින් කිවහොත්, ඔබ ගණනය කළ යුතුය අපේක්ෂිත සංඛ්යාතහදිසි අවස්ථා වගුවේ අනුරූප සෛල සඳහා. එය කරන්නේ කෙසේද? අත්හදා බැලීමේ දී, මුළු මීයන් 38 ක් මිය ගිය අතර, එය සම්බන්ධ වූ මුළු සතුන් සංඛ්යාවෙන් 34.2% කි. ප්රතිදේහ පරිපාලනය මීයන්ගේ පැවැත්මට බලපාන්නේ නැතිනම්, පර්යේෂණාත්මක කණ්ඩායම් දෙකෙහිම මරණ අනුපාතයම නිරීක්ෂණය කළ යුතුය, එනම් 34.2%. 57 සහ 54 න් 34.2% කොපමණ දැයි ගණනය කිරීමෙන් අපට 19.5 සහ 18.5 ලැබේ. මේවා අපගේ පර්යේෂණාත්මක කණ්ඩායම්වල අපේක්ෂිත මරණ අනුපාත වේ. අපේක්ෂිත පැවැත්ම අනුපාත ගණනය කරනු ලබන්නේ ඒ හා සමාන ආකාරයකින් ය: මුළු මීයන් 73 ක් හෝ මුළු සංඛ්යාවෙන් 65.8% ක් දිවි ගලවා ගත් බැවින්, අපේක්ෂිත පැවැත්ම අනුපාත 37.5 සහ 35.5 වනු ඇත. අපි දැන් අපේක්ෂිත සංඛ්යාත සමඟ, නව හදිසි අවස්ථා වගුවක් නිර්මාණය කරමු:
මරු |
දිවි ගලවා ගත් අය |
මුළු |
|
බැක්ටීරියා + සෙරුමය |
|||
බැක්ටීරියා පමණි |
|||
මුළු |
අපට පෙනෙන පරිදි, අපේක්ෂිත සංඛ්යාත නිරීක්ෂණය කරන ලද ඒවාට වඩා බෙහෙවින් වෙනස් ය, i.e. ප්රතිදේහ පරිපාලනය රෝග කාරකය ආසාදනය වූ මීයන්ගේ පැවැත්මට බලපෑමක් ඇති කරන බව පෙනේ. Pearson goodness-of-fit test \(\chi^2\) භාවිතයෙන් අපට මෙම හැඟීම ප්රමාණ කළ හැක:
\[\chi^2 = \sum_()\frac((f_o - f_e)^2)(f_e),\]
මෙහි \(f_o\) සහ \(f_e\) යනු පිළිවෙලින් නිරීක්ෂණය කරන ලද සහ අපේක්ෂිත සංඛ්යාත වේ. සාරාංශය මේසයේ සියලුම සෛල හරහා සිදු කෙරේ. ඉතින්, අපි සලකා බලනු ලබන උදාහරණය සඳහා
\[\chi^2 = (13 – 19.5)^2/19.5 + (44 – 37.5)^2/37.5 + (25 – 18.5)^2/18.5 + (29 – 35.5)^2/35.5 = \]
\(\chi^2\) හි ප්රතිඵලයක් ලෙස ලැබෙන අගය ශුන්ය කල්පිතය ප්රතික්ෂේප කිරීමට තරම් විශාලද? මෙම ප්රශ්නයට පිළිතුරු සැපයීම සඳහා නිර්ණායකයේ අනුරූප විවේචනාත්මක අගය සොයා ගැනීම අවශ්ය වේ. \(\chi^2\) සඳහා නිදහසේ අංශක ගණන \(df = (R - 1)(C - 1)\) ලෙස ගණනය කෙරේ, මෙහි \(R\) සහ \(C\) යනු අංකය වේ. වගු සංයුක්තයේ පේළි සහ තීරු. අපගේ නඩුවේදී \(df = (2 -1)(2 - 1) = 1\). නිදහසේ අංශක ගණන දැන ගැනීමෙන්, අපට දැන් සම්මත R ශ්රිතය qchisq() භාවිතා කර \(\chi^2\) තීරණාත්මක අගය පහසුවෙන් සොයාගත හැක.
මේ අනුව, නිදහසේ එක් උපාධියක් සමඟ, අවස්ථා 5% කදී පමණක් \(\chi^2\) නිර්ණායකයේ අගය 3.841 ඉක්මවයි. අප ලබාගත් අගය, 6.79, මෙම තීරණාත්මක අගය සැලකිය යුතු ලෙස ඉක්මවා යන අතර, ප්රතිදේහ පරිපාලනය සහ ආසාදිත මීයන්ගේ පැවැත්ම අතර සම්බන්ධයක් නොමැති බවට ශුන්ය උපකල්පනය ප්රතික්ෂේප කිරීමට අපට අයිතිය ලබා දෙයි. මෙම උපකල්පනය ප්රතික්ෂේප කිරීමෙන්, අපි 5% ට වඩා අඩු සම්භාවිතාවක් සමඟ වැරදි වීමේ අවදානමක් ගනිමු.
\(\chi^2\) නිර්ණායකය සඳහා ඉහත සූත්රය 2x2 ප්රමාණයේ අවිනිශ්චිත වගු සමඟ වැඩ කරන විට තරමක් පුම්බා ඇති අගයන් ලබා දෙන බව සටහන් කළ යුතුය. හේතුව \(\chi^2\) නිර්ණායකයේ ව්යාප්තියම අඛණ්ඩ වන අතර ද්විමය ලක්ෂණවල සංඛ්යාත ("මියගිය" / "ගැලවී ඇත") නිර්වචනය අනුව විවික්ත වේ. මේ සම්බන්ධයෙන්, නිර්ණායකය ගණනය කිරීමේදී, ඊනියා හඳුන්වා දීම සිරිතකි. අඛණ්ඩතාව නිවැරදි කිරීම, හෝ යේට්ස් සංශෝධනය :
\[\chi^2_Y = \sum_()\frac((|f_o - f_e| - 0.5)^2)(f_e).\]
"යේට්ස් සමග s Chi-squared test" අඛණ්ඩ නිවැරදි කිරීමේ දත්ත: මීයන් X-squared = 5.7923, df = 1, p-value = 0.0161
අපට පෙනෙන පරිදි, R ස්වයංක්රීයව Yates අඛණ්ඩ නිවැරදි කිරීම යොදයි ( Pearson's Chi-squared test with Yates" අඛණ්ඩතාව නිවැරදි කිරීම) වැඩසටහන මගින් ගණනය කරන ලද \(\chi^2\) හි අගය 5.79213 විය. 1% (p-අගය = 0.0161) වැනි සම්භාවිතාවක් සමඟ වැරදි වීමේ අවදානමක් ඇතිව ප්රතිදේහ බලපෑමක් නැත යන ශුන්ය කල්පිතය අපට ප්රතික්ෂේප කළ හැක.
ජීව විද්යාත්මක සංසිද්ධි පිළිබඳ ප්රමාණාත්මක අධ්යයනය සඳහා මෙම සංසිද්ධීන් පැහැදිලි කිරීමට උපකල්පන නිර්මාණය කිරීම අවශ්ය වේ. විශේෂිත උපකල්පනයක් පරීක්ෂා කිරීම සඳහා, විශේෂ අත්හදා බැලීම් මාලාවක් සිදු කරනු ලබන අතර, ලබාගත් සත්ය දත්ත මෙම කල්පිතයට අනුව න්යායාත්මකව අපේක්ෂිත ඒවා සමඟ සංසන්දනය කරනු ලැබේ. අහඹු සිදුවීමක් තිබේ නම්, කල්පිතය පිළිගැනීමට මෙය ප්රමාණවත් හේතුවක් විය හැකිය. පර්යේෂණාත්මක දත්ත න්යායාත්මකව අපේක්ෂිත ඒවා සමඟ හොඳින් එකඟ නොවන්නේ නම්, යෝජිත කල්පිතයේ නිවැරදිභාවය පිළිබඳව විශාල සැකයක් මතු වේ.
සැබෑ දත්ත අපේක්ෂිත (උපකල්පිත) ට අනුරූප වන මට්ටම chi-square පරීක්ෂණයෙන් මනිනු ලැබේ:
- ලක්ෂණයේ සැබෑ නිරීක්ෂිත අගය මම-දී ඇති කණ්ඩායමක් සඳහා න්යායාත්මකව අපේක්ෂිත අංකය හෝ ලකුණ (දර්ශකය), කේ- දත්ත කණ්ඩායම් ගණන.
නිර්ණායකය 1900 දී K. Pearson විසින් යෝජනා කරන ලද අතර සමහර විට එය Pearson නිර්ණායකය ලෙස හැඳින්වේ.
කාර්ය.එක් දෙමාපියෙකුගෙන් සාධකයක් සහ අනෙකාගෙන් සාධකයක් උරුම වූ දරුවන් 164 දෙනෙකු අතර, සාධකය සහිත දරුවන් 46 ක්, සාධකය සමඟ 50 ක්, දෙදෙනාම සමඟ 68 ක් සිටියහ. කණ්ඩායම් අතර 1:2:1 අනුපාතයක් සඳහා අපේක්ෂිත සංඛ්යාත ගණනය කරන්න සහ පියර්සන් පරීක්ෂණය භාවිතයෙන් අනුභූතික දත්තවල එකඟතාවයේ මට්ටම තීරණය කරන්න.
විසඳුමක්:නිරීක්ෂණය කරන ලද සංඛ්යාතවල අනුපාතය 46:68:50, න්යායාත්මකව අපේක්ෂිත 41:82:41.
අපි වැදගත්කම මට්ටම 0.05 ලෙස සකසමු. නිදහසේ අංශක ගණන සමාන වීමත් සමඟ මෙම වැදගත්කමේ මට්ටම සඳහා පියර්සන් නිර්ණායකයේ වගු අගය 5.99 බවට පත් විය. එබැවින්, න්යායික දත්ත වලට පර්යේෂණාත්මක දත්ත අනුරූප වීම පිළිබඳ උපකල්පනය පිළිගත හැකි බැවින්, .
chi-square පරීක්ෂණය ගණනය කිරීමේදී, බෙදා හැරීමේ අනිවාර්ය සාමාන්යය සඳහා අපි තවදුරටත් කොන්දේසි සකස් නොකරන බව සලකන්න. අපගේ උපකල්පනවලදී අපට තෝරා ගැනීමට නිදහස ඇති ඕනෑම බෙදාහැරීමක් සඳහා chi-square පරීක්ෂණය භාවිතා කළ හැක. මෙම නිර්ණායකයේ යම් විශ්වීයත්වයක් තිබේ.
පියර්සන් පරීක්ෂණයේ තවත් යෙදුමක් වන්නේ ආනුභවික ව්යාප්තිය Gaussian සාමාන්ය ව්යාප්තිය සමඟ සංසන්දනය කිරීමයි. එපමනක් නොව, එය බෙදා හැරීමේ සාමාන්යය පරීක්ෂා කිරීම සඳහා නිර්ණායක සමූහයක් ලෙස වර්ග කළ හැක. එකම සීමාව වන්නේ මෙම නිර්ණායකය භාවිතා කරන විට මුළු අගයන් (විකල්ප) ප්රමාණවත් තරම් විශාල විය යුතුය (අවම වශයෙන් 40), සහ තනි පන්තිවල (අන්තර්වල) අගයන් ගණන අවම වශයෙන් 5 ක් විය යුතුය. එසේ නොමැති නම්, යාබද කාල පරතරයන් ඒකාබද්ධ කළ යුතුය. බෙදා හැරීමේ සාමාන්යභාවය පරීක්ෂා කිරීමේදී නිදහසේ අංශක ගණන ගණනය කළ යුත්තේ:
ධීවර නිර්ණායකය.
මෙම පරාමිතික පරීක්ෂණය සාමාන්යයෙන් බෙදා හරින ලද ජනගහනවල විචලනයන් සමාන බවට ශුන්ය කල්පිතය පරීක්ෂා කිරීමට භාවිතා කරයි.
![]() හෝ.
හෝ.
කුඩා නියැදි ප්රමාණ සමඟ, ශිෂ්ය පරීක්ෂණය භාවිතා කිරීම නිවැරදි විය හැක්කේ විචලනයන් සමාන නම් පමණි. එබැවින්, නියැදි මාධ්යවල සමානාත්මතාවය පරීක්ෂා කිරීමට පෙර, ශිෂ්ය ටී පරීක්ෂණය භාවිතා කිරීමේ වලංගුභාවය සහතික කිරීම අවශ්ය වේ.
කොහෙද එන් 1 , එන් 2 සාම්පල ප්රමාණ, 1 , 2 මෙම සාම්පල සඳහා නිදහසේ අංශක ගණන.
වගු භාවිතා කරන විට, විශාල විසරණයක් සහිත නියැදියක් සඳහා නිදහස් අංශක ගණන වගු තීරු අංකය ලෙසත්, කුඩා විසරණය සඳහා වගු පේළි අංකය ලෙසත් තෝරාගෙන ඇති බව ඔබ අවධානය යොමු කළ යුතුය.
වැදගත්කම මට්ටම සඳහා, අපි ගණිතමය සංඛ්යාලේඛන වගු වලින් වගු අගය සොයා ගනිමු. එසේ නම්, තෝරාගත් වැදගත්කම මට්ටම සඳහා විචල්යයන්ගේ සමානාත්මතාවයේ උපකල්පනය ප්රතික්ෂේප කරනු ලැබේ.
උදාහරණයක්.හාවන්ගේ ශරීර බරට කොබෝල්ට් වල බලපෑම අධ්යයනය කරන ලදී. අත්හදා බැලීම සතුන් කණ්ඩායම් දෙකක් මත සිදු කරන ලදී: පර්යේෂණාත්මක සහ පාලනය. පර්යේෂණාත්මක විෂයයන් සඳහා කෝබෝල්ට් ක්ලෝරයිඩ් ජලීය ද්රාවණයක් ආකාරයෙන් ආහාර අතිරේකයක් ලැබුණි. පරීක්ෂණය අතරතුර, බර වැඩිවීම ග්රෑම් වලින්:
|
පාලනය කරන්න |
|

මෙම ලිපියෙන් අපි සංඥා අතර යැපීම අධ්යයනය කිරීම හෝ ඔබ කැමති පරිදි - අහඹු අගයන්, විචල්යයන් ගැන කතා කරමු. විශේෂයෙන්ම, අපි Chi-square පරීක්ෂණය භාවිතයෙන් ලක්ෂණ අතර රඳා පැවැත්මේ මිනුමක් හඳුන්වා දෙන ආකාරය සහ සහසම්බන්ධතා සංගුණකය සමඟ සංසන්දනය කරන්නේ කෙසේදැයි බලමු.
මෙය අවශ්ය විය හැක්කේ ඇයි? උදාහරණයක් ලෙස, ණය ලකුණු ගොඩනැගීමේදී ඉලක්ක විචල්යය මත වැඩිපුර රඳා පවතින්නේ කුමන විශේෂාංගද යන්න තේරුම් ගැනීම සඳහා - සේවාලාභියාගේ පෙරනිමියේ සම්භාවිතාව තීරණය කිරීම. නැතහොත්, මගේ නඩුවේ මෙන්, වෙළඳ රොබෝවක් වැඩසටහන්ගත කිරීම සඳහා භාවිතා කළ යුතු දර්ශක මොනවාදැයි තේරුම් ගන්න.
වෙනමම, මම දත්ත විශ්ලේෂණය සඳහා C# භාෂාව භාවිතා කරන බව සටහන් කිරීමට කැමැත්තෙමි. සමහර විට මේ සියල්ල දැනටමත් R හෝ Python හි ක්රියාත්මක කර ඇත, නමුත් මා සඳහා C# භාවිතා කිරීමෙන් මාතෘකාව විස්තරාත්මකව තේරුම් ගැනීමට මට ඉඩ සලසයි, එපමනක් නොව, එය මගේ ප්රියතම ක්රමලේඛන භාෂාවයි.
අපි ඉතා සරල උදාහරණයකින් පටන් ගනිමු, අහඹු සංඛ්යා උත්පාදකයක් භාවිතයෙන් Excel හි තීරු හතරක් සාදන්න:
x=RANDBETWEEN(-100,100)
වයි =x*10+20
Z =x*x
ටී=RANDBETWEEN(-100,100)
ඔබට පෙනෙන පරිදි, විචල්යය වයිරේඛීයව රඳා පවතී x; විචල්ය Zචතුරස්රාකාරව රඳා පවතී x; විචල්යයන් xසහ ටීස්වාධීන. මම මෙම තේරීම හිතාමතාම කළෙමි, මන්ද අපි අපගේ යැපීම් මිනුම සහසම්බන්ධතා සංගුණකය සමඟ සංසන්දනය කරන බැවිනි. දන්නා පරිදි, සසම්භාවී විචල්ය දෙකක් අතර ඒවා අතර "දැඩිම" යැපීම රේඛීය නම් එය මොඩියුල 1 ට සමාන වේ. ස්වාධීන අහඹු විචල්ය දෙකක් අතර ශුන්ය සහසම්බන්ධයක් ඇත, නමුත් සහසම්බන්ධතා සංගුණකයේ ශුන්යයට සමානාත්මතාවය ස්වාධීනත්වය අදහස් නොවේ. මීළඟට අපි මෙය බලමු විචල්ය උදාහරණය භාවිතා කරමින් xසහ Z.
ගොනුව data.csv ලෙස සුරකින්න සහ පළමු ඇස්තමේන්තු ආරම්භ කරන්න. පළමුව, අගයන් අතර සහසම්බන්ධතා සංගුණකය ගණනය කරමු. මම ලිපියට කේතය ඇතුළු කළේ නැත, එය මගේ ගිතුබ් එකේ ඇත. හැකි සියලුම යුගල සඳහා අපි සහසම්බන්ධය ලබා ගනිමු:

රේඛීයව රඳා පවතින බව දැකිය හැකිය xසහ වයිසහසම්බන්ධතා සංගුණකය 1. නමුත් xසහ Zඅප යැපීම පැහැදිලිව සකසන නමුත් එය 0.01 ට සමාන වේ Z=x*x. පැහැදිලිවම, අපට ඇබ්බැහි වීම වඩා හොඳින් "හැඟෙන" මිනුමක් අවශ්ය වේ. නමුත් Chi-square පරීක්ෂණයට යාමට පෙර, හදිසි අනුකෘතියක් යනු කුමක්දැයි බලමු.
අනපේක්ෂිත න්යාසයක් ගොඩනැගීම සඳහා, අපි විචල්ය අගයන් පරාසය කාල පරතරයන්ට බෙදන්නෙමු (හෝ වර්ගීකරණය කරන්න). මෙය කිරීමට බොහෝ ක්රම තිබේ, නමුත් විශ්වීය ක්රමයක් නොමැත. ඒවායින් සමහරක් විචල්යයන් එකම සංඛ්යාවක් අඩංගු වන පරිදි විරාමවලට බෙදා ඇත, අනෙක් ඒවා සමාන දිග ප්රාන්තරවලට බෙදා ඇත. මම පෞද්ගලිකව මෙම ප්රවේශයන් ඒකාබද්ධ කිරීමට කැමතියි. මම මෙම ක්රමය භාවිතා කිරීමට තීරණය කළෙමි: මම විචල්යයෙන් මැට් ලකුණු අඩු කරමි. අපේක්ෂාවන්, පසුව සම්මත අපගමනය ඇස්තමේන්තු මගින් ප්රතිඵලය බෙදන්න. වෙනත් වචන වලින් කිවහොත්, මම අහඹු විචල්යය කේන්ද්ර කර සාමාන්යකරණය කරමි. ලැබෙන අගය සංගුණකයකින් ගුණ කරනු ලැබේ (මෙම උදාහරණයේ එය 1 වේ), ඉන්පසු සෑම දෙයක්ම ආසන්නතම සම්පූර්ණ අංකයට වට කර ඇත. ප්රතිදානය යනු int වර්ගයේ විචල්යයකි, එය class identifier වේ.
ඒ නිසා අපි අපේ සලකුණු ගනිමු xසහ Z, අපි ඉහත විස්තර කර ඇති ආකාරයට වර්ගීකරණය කරමු, ඉන්පසු අපි එක් එක් පන්තියේ පෙනුමේ සංඛ්යාව සහ සම්භාවිතා සහ විශේෂාංග යුගල පෙනුමේ සම්භාවිතාව ගණනය කරමු:

මෙය ප්රමාණයෙන් න්යාසයකි. මෙහි රේඛාවල - විචල්ය පන්තිවල සිදුවීම් සංඛ්යාව x, තීරු තුළ - විචල්යයේ පන්තිවල සිදුවීම් සංඛ්යාව Z, සෛල තුළ - එකවර පන්ති යුගල පෙනුම සංඛ්යාව. උදාහරණයක් ලෙස, විචල්යය සඳහා 0 පන්තිය 865 වතාවක් සිදු විය x, විචල්යයක් සඳහා 823 වාරයක් Zසහ කිසි විටෙකත් යුගලයක් නොතිබුණි (0,0). සියලුම අගයන් 3000 න් බෙදීමෙන් සම්භාවිතාවන් වෙත යමු (මුළු නිරීක්ෂණ ගණන):

අපි විශේෂාංග වර්ගීකරණය කිරීමෙන් පසු ලබාගත් හදිසි අනුකෘතියක් ලබා ගත්තෙමු. දැන් නිර්ණායකය ගැන සිතීමට කාලයයි. නිර්වචනය අනුව, මෙම අහඹු විචල්ය මගින් ජනනය වන සිග්මා වීජ ගණිතය ස්වාධීන නම් අහඹු විචල්යයන් ස්වාධීන වේ. සිග්මා වීජ ගණිතයේ ස්වාධීනත්වය ඔවුන්ගෙන් සිදුවීම් යුගල වශයෙන් ස්වාධීනත්වය අදහස් කරයි. මෙම සිදුවීම්වල සම්භාවිතාවේ ගුණිතයට සමාන නම්, ඒවායේ ඒකාබද්ධ සිදුවීමේ සම්භාවිතාව ස්වාධීන ලෙස හැඳින්වේ: Pij = Pi*Pj. නිර්ණායකය ගොඩනැගීමට අප භාවිතා කරන්නේ මෙම සූත්රයයි.
ශුන්ය කල්පිතය: වර්ගීකරණය කරන ලද සංඥා xසහ Zස්වාධීන. එයට සමාන: අහඹු අනුකෘතියේ ව්යාප්තිය නිශ්චිතව දක්වා ඇත්තේ විචල්ය පන්ති (පේළි සහ තීරු වල සම්භාවිතාව) ඇතිවීමේ සම්භාවිතාවන් මගිනි. නැතහොත් මෙය: න්යාස සෛල සොයාගනු ලබන්නේ පේළි සහ තීරුවල අනුරූප සම්භාවිතාවේ ගුණිතය මගිනි. තීරණ රීතිය ගොඩනැගීම සඳහා අපි ශුන්ය කල්පිතයේ මෙම සූත්රගත කිරීම භාවිතා කරමු: අතර සැලකිය යුතු විෂමතාවක් Pijසහ Pi*Pjශුන්ය කල්පිතය ප්රතික්ෂේප කිරීම සඳහා පදනම වනු ඇත.
විචල්යයක 0 පන්තියේ දර්ශනය වීමේ සම්භාවිතාව යැයි සිතමු x. අපේ මුළු nදී පන්ති xසහ එම්දී පන්ති Z. න්යාස ව්යාප්තිය සැකසීමට නම් අපි මේවා දැන සිටිය යුතු බව පෙනේ nසහ එම්සම්භාවිතාව. නමුත් ඇත්ත වශයෙන්ම, අපි දන්නවා නම් n-1සඳහා සම්භාවිතාව x, පසුව දෙවැන්න සොයාගනු ලබන්නේ අනෙක් ඒවායේ එකතුව 1 න් අඩු කිරීමෙන් ය. මේ අනුව, අප දැනගත යුතු හදිසි අනුකෘතියේ ව්යාප්තිය සොයා ගැනීමට l=(n-1)+(m-1)අගයන්. නැත්නම් අපිට තියෙනවද එල්-dimensional parametric space, අපට අවශ්ය ව්යාප්තිය ලබා දෙන දෛශිකය. චි-චතුරස්ර සංඛ්යාලේඛනය මේ ආකාරයෙන් පෙනෙනු ඇත: 
සහ, ෆිෂර්ගේ ප්රමේයය අනුව, චි-චතුරස්ර ව්යාප්තියක් ඇත n*m-l-1=(n-1)(m-1)නිදහසේ උපාධි.
අපි වැදගත්කම මට්ටම 0.95 ලෙස සකසමු (හෝ I වර්ගයේ දෝෂයක සම්භාවිතාව 0.05 වේ). දී ඇති වැදගත් මට්ටමක් සහ උදාහරණයෙන් නිදහස් වීමේ මට්ටම් සඳහා චි වර්ග ව්යාප්තියේ ප්රමාණය සොයා ගනිමු (n-1)(m-1)=4*3=12: 21.02606982. විචල්ය සඳහා Chi-square සංඛ්යාලේඛනය ම ය xසහ Z 4088.006631 ට සමාන වේ. ස්වාධීනත්වය පිළිබඳ කල්පිතය නොපිළිගන්නා බව පැහැදිලිය. Chi-square සංඛ්යාලේඛනයේ එළිපත්ත අගයට අනුපාතය සලකා බැලීම පහසුය - මෙම අවස්ථාවේ දී එය සමාන වේ Chi2Coeff=194.4256186. මෙම අනුපාතය 1 ට වඩා අඩු නම්, ස්වාධීනත්වය පිළිබඳ උපකල්පනය එය වැඩි නම්, එසේ නොවේ. සියලුම විශේෂාංග යුගල සඳහා මෙම අනුපාතය සොයා ගනිමු:

මෙතන සාධකය 1සහ සාධකය2- විශේෂාංග නම්
src_cnt1සහ src_cnt2- ආරම්භක ලක්ෂණ වල අද්විතීය අගයන් ගණන
mod_cnt1සහ mod_cnt2- වර්ගීකරණයෙන් පසු අද්විතීය විශේෂාංග අගයන් ගණන
chi2- චි-චතුරස්ර සංඛ්යාලේඛන
chi2max- 0.95 ක වැදගත්කම මට්ටමක් සඳහා Chi-square සංඛ්යා ලේඛනයේ එළිපත්ත අගය
chi2Coeff- චයි-චතුරශ්රය සංඛ්යාලේඛනයේ සීමාවේ අගයට අනුපාතය
corr- සහසම්බන්ධතා සංගුණකය
ඔවුන් ස්වාධීන බව දැකිය හැකිය (chi2coeff<1) получились следующие пары признаков - (X,T), (Y,T) සහ ( Z,T), විචල්යය සිට තාර්කික වේ ටීඅහඹු ලෙස ජනනය වේ. විචල්යයන් xසහ Zරඳා පවතී, නමුත් රේඛීයව රඳා පවතිනවාට වඩා අඩුය xසහ වයි, එය ද තාර්කික ය.
මම මෙම දර්ශක ගණනය කරන උපයෝගිතා කේතය github මත පළ කළෙමි, එහි data.csv ගොනුව ද ඇත. උපයෝගිතා csv ගොනුවක් ආදානය ලෙස ගෙන සියලු තීරු යුගල අතර පරායත්තතා ගණනය කරයි: PtProject.Dependency.exe data.csv
බෙදා හැරීම. පියර්සන් ව්යාප්තිය සම්භාවිතා ඝනත්වය ... විකිපීඩියාව
chi-square බෙදා හැරීම- chi වර්ග බෙදාහැරීම - මාතෘකා තොරතුරු ආරක්ෂාව EN chi වර්ග බෙදාහැරීම ... තාක්ෂණික පරිවර්තක මාර්ගෝපදේශය
chi-square බෙදා හැරීම- 0 සිට 0 දක්වා අගයන් සහිත අඛණ්ඩ අහඹු විචල්යයක සම්භාවිතා ව්යාප්තිය, එහි ඝනත්වය සූත්රය මගින් ලබා දී ඇත, එහිදී පරාමිතිය සඳහා 0 =1,2,...; - ගැමා ශ්රිතය. උදාහරණ. 1) ස්වාධීන සාමාන්යකරණය වූ අහඹු අහඹු ලෙස වර්ගවල එකතුව... ... සමාජ විද්යාත්මක සංඛ්යාලේඛන ශබ්දකෝෂය
CHI-චතුරශ්රය බෙදාහැරීම (chi2)- සසම්භාවී විචල්ය chi2 බෙදා හැරීම සාමාන්ය ව්යාප්තියකින් මධ්යන්ය (සහ විචල්ය q2, එවිට chi2 = (X1 u)2/q2, නියැදි ප්රමාණය නම්. අහඹු ලෙස N දක්වා වැඩි විය, පසුව chi2 = ……
සම්භාවිතා ඝනත්වය ... විකිපීඩියා
- (Snedecor බෙදාහැරීම) සම්භාවිතා ඝනත්වය ... විකිපීඩියා
ධීවර ව්යාප්තිය සම්භාවිතා ඝනත්වය බෙදා හැරීමේ ශ්රිතය සමඟ සංඛ්යාවක පරාමිතීන් ... විකිපීඩියා
සම්භාවිතා න්යාය සහ ගණිතමය සංඛ්යාලේඛනවල මූලික සංකල්පවලින් එකකි. නවීන ප්රවේශය සමඟ, ගණිතමය වශයෙන් අධ්යයනය කරන අහඹු සංසිද්ධියේ ආකෘතිය, අනුරූප සම්භාවිතා අවකාශය (W, S, P) ගනු ලැබේ, එහිදී W යනු ප්රාථමික... ගණිතමය විශ්වකෝෂය
ගැමා ව්යාප්තිය සම්භාවිතා ඝනත්වය බෙදා හැරීමේ කාර්යය පරාමිතීන් ... විකිපීඩියා
බෙදාහැරීම එෆ්- සසම්භාවී විචල්යයක න්යායික සම්භාවිතා ව්යාප්තිය F. සාමාන්ය ජනගහනයකින් N ප්රමාණයේ අහඹු සාම්පල ස්වාධීනව අඳින්නේ නම්, එක් එක් නිදහසේ උපාධිය සමඟ චි-චතුරස්ර ව්යාප්තියක් ජනනය කරයි = N. එවැනි දෙකක අනුපාතය... ... මනෝවිද්යාව පිළිබඳ පැහැදිලි කිරීමේ ශබ්දකෝෂය
පොත්
- ගැටළු වල සම්භාවිතා න්යාය සහ ගණිතමය සංඛ්යාලේඛන: ගැටළු සහ අභ්යාස 360 කට වඩා වැඩි ප්රමාණයක්, Borzykh D.. යෝජිත අත්පොතෙහි විවිධ මට්ටමේ සංකීර්ණතා වල ගැටළු අඩංගු වේ. කෙසේ වෙතත්, ප්රධාන වශයෙන් අවධාරණය වන්නේ මධ්යම සංකීර්ණත්වයේ කාර්යයන් මතය. මෙය සිසුන් දිරිමත් කිරීම සඳහා හිතාමතාම සිදු කරනු ලැබේ ...
- ගැටළු වල සම්භාවිතා න්යාය සහ ගණිතමය සංඛ්යාලේඛන. කාර්යයන් සහ අභ්යාස 360 කට වඩා, Borzykh D.A.. යෝජිත අත්පොතෙහි විවිධ මට්ටමේ සංකීර්ණතාවල කාර්යයන් අඩංගු වේ. කෙසේ වෙතත්, ප්රධාන වශයෙන් අවධාරණය වන්නේ මධ්යම සංකීර්ණත්වයේ කාර්යයන් මතය. මෙය සිසුන් දිරිමත් කිරීම සඳහා හිතාමතාම සිදු කරනු ලැබේ ...







