Estimation des niveaux de signification des coefficients de l'équation de régression. Vérification de la signification de l'équation de régression
Une fois l'équation de régression construite et sa précision estimée à l'aide du coefficient de détermination, il reste question ouverte en raison de ce que cette précision est atteinte et, par conséquent, peut-on faire confiance à cette équation. Le fait est que l'équation de régression n'a pas été construite selon population, qui est inconnu, mais à partir d'un échantillon de celui-ci. Les points de la population générale tombent dans l'échantillon de manière aléatoire, par conséquent, conformément à la théorie des probabilités, entre autres cas, il est possible que l'échantillon de la population générale «large» se révèle «étroit» (Fig. 15) .
Riz. quinze. Variante possible points de vie dans l'échantillon de la population générale.
Dans ce cas:
a) l'équation de régression construite sur l'échantillon peut différer significativement de l'équation de régression pour la population générale, ce qui entraînera des erreurs de prévision ;
b) le coefficient de détermination et d'autres caractéristiques de précision s'avéreront déraisonnablement élevés et induiront en erreur sur les qualités prédictives de l'équation.
Dans le cas limite, la variante n'est pas exclue, lorsque de la population générale, qui est un nuage avec l'axe principal parallèle à l'axe horizontal (il n'y a pas de lien entre les variables), un échantillon sera obtenu grâce à une sélection aléatoire, dont l'axe principal sera incliné par rapport à l'axe. Ainsi, les tentatives de prédire les prochaines valeurs de la population générale sur la base de données d'échantillon sont lourdes non seulement d'erreurs dans l'évaluation de la force et de la direction de la relation entre les variables dépendantes et indépendantes, mais également du danger de trouver un relation entre des variables là où il n'y en a pas.
En l'absence d'information sur tous les points de la population générale, la seule façon de réduire les erreurs dans le premier cas est d'utiliser une méthode d'estimation des coefficients de l'équation de régression qui assure leur impartialité et leur efficacité. Et la probabilité d'apparition du deuxième cas peut être considérablement réduite du fait qu'une propriété de la population générale avec deux variables indépendantes l'une de l'autre est connue a priori - c'est cette connexion qui y est absente. Cette réduction est obtenue en vérifiant signification statistique l'équation de régression résultante.
L'une des options de vérification les plus couramment utilisées est la suivante. Pour l'équation de régression résultante, la caractéristique -statistique - de la précision de l'équation de régression est déterminée, qui est le rapport de la partie de la variance de la variable dépendante qui est expliquée par l'équation de régression à la partie inexpliquée (résiduelle) de la variance. L'équation pour déterminer les -statistiques dans le cas d'une régression multivariée est :

où : - variance expliquée - partie de la variance de la variable dépendante Y, qui est expliquée par l'équation de régression ;
Variance résiduelle - partie de la variance de la variable dépendante Y qui n'est pas expliquée par l'équation de régression, sa présence est une conséquence de l'action d'une composante aléatoire ;
Nombre de points dans l'échantillon ;
Le nombre de variables dans l'équation de régression.
Comme on peut le voir à partir de la formule ci-dessus, les variances sont définies comme le quotient de la division de la somme des carrés correspondante par le nombre de degrés de liberté. Le nombre de degrés de liberté est le nombre minimum requis de valeurs de la variable dépendante, qui sont suffisantes pour obtenir la caractéristique d'échantillon souhaitée et qui peuvent varier librement, étant donné que toutes les autres quantités utilisées pour calculer la caractéristique souhaitée sont connues pour cela. goûter.
Pour obtenir la variance résiduelle, les coefficients de l'équation de régression sont nécessaires. Dans le cas d'un hammam régression linéaire il y a deux coefficients, donc, conformément à la formule (en supposant ), le nombre de degrés de liberté est égal à . Cela signifie que pour déterminer la variance résiduelle, il suffit de connaître les coefficients de l'équation de régression et uniquement les valeurs de la variable dépendante de l'échantillon. Les deux valeurs restantes peuvent être calculées à partir de ces données et ne sont donc pas librement variables.
Pour calculer la variance expliquée, les valeurs de la variable dépendante ne sont pas du tout nécessaires, car elles peuvent être calculées en connaissant les coefficients de régression des variables indépendantes et la variance de la variable indépendante. Pour le voir, il suffit de rappeler l'expression donnée plus haut ![]() . Par conséquent, le nombre de degrés de liberté pour la variance résiduelle est égal au nombre de variables indépendantes dans l'équation de régression (pour la régression linéaire appariée).
. Par conséquent, le nombre de degrés de liberté pour la variance résiduelle est égal au nombre de variables indépendantes dans l'équation de régression (pour la régression linéaire appariée).
Par conséquent, le critère - pour l'équation de régression linéaire appariée est déterminé par la formule :
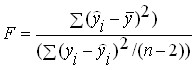 .
.
En théorie des probabilités, il a été prouvé que le -critère de l'équation de régression obtenue pour un échantillon de la population générale dans lequel il n'y a pas de lien entre la variable dépendante et indépendante a une distribution de Fisher, qui est assez bien étudiée. De ce fait, pour toute valeur du -critère, il est possible de calculer la probabilité de son occurrence et inversement, de déterminer la valeur du -critère qu'il ne peut pas dépasser avec une probabilité donnée.
Pour effectuer un test statistique de la signification de l'équation de régression, une hypothèse nulle est formulée sur l'absence de relation entre les variables (tous les coefficients des variables sont égaux à zéro) et le niveau de signification est sélectionné.
Le niveau de signification est la probabilité acceptable de faire une erreur de type I - rejetant l'hypothèse nulle correcte à la suite d'un test. Dans ce cas, commettre une erreur de type I signifie reconnaître à partir de l'échantillon la présence d'une relation entre les variables dans la population générale, alors qu'en fait elle n'existe pas.
Le niveau de signification est généralement considéré comme étant de 5 % ou de 1 %. Plus le seuil de signification est élevé (plus ) est petit, plus le niveau de fiabilité du test est élevé, c'est-à-dire plus grande est la chance d'éviter l'erreur d'échantillonnage de l'existence d'une relation dans la population de variables qui ne sont en fait pas liées. Mais avec une augmentation du niveau de signification, le risque de commettre une erreur du second type augmente - rejeter l'hypothèse nulle correcte, c'est-à-dire ne pas remarquer dans l'échantillon la relation réelle des variables dans la population générale. Par conséquent, selon l'erreur qui a un grand Conséquences négatives, choisissez l'un ou l'autre niveau de signification.
Pour le niveau de signification sélectionné selon la distribution de Fisher, une valeur tabulaire est déterminée, dont la probabilité de dépassement dans l'échantillon de puissance , obtenu à partir de la population générale sans relation entre les variables, ne dépasse pas le niveau de signification. par rapport à la valeur réelle du critère de l'équation de régression .
Si la condition est remplie, alors la détection erronée d'une relation avec la valeur du critère égale ou supérieure dans l'échantillon de la population générale avec des variables non liées se produira avec une probabilité inférieure au seuil de signification. Selon le "très événements rares ne se produit pas », nous arrivons à la conclusion que la relation entre les variables établies par l'échantillon est également présente dans la population générale à partir de laquelle elle a été obtenue.
S'il s'avère, alors l'équation de régression n'est pas statistiquement significative. En d'autres termes, il existe une probabilité réelle qu'une relation entre des variables qui n'existe pas dans la réalité se soit établie dans l'échantillon. Une équation qui échoue au test de signification statistique est traitée de la même manière qu'un médicament périmé.
Tee - ces médicaments ne sont pas nécessairement gâtés, mais comme il n'y a aucune confiance dans leur qualité, il est préférable de ne pas les utiliser. Cette règle ne protège pas contre toutes les erreurs, mais elle permet d'éviter les plus grossières, ce qui est aussi assez important.
La deuxième option de vérification, plus pratique dans le cas de l'utilisation de feuilles de calcul, est une comparaison de la probabilité d'occurrence de la valeur de critère obtenue avec le seuil de signification. Si cette probabilité est inférieure au seuil de signification , l'équation est statistiquement significative, sinon elle ne l'est pas.
Après avoir vérifié la signification statistique de l'équation de régression, il est généralement utile, en particulier pour les dépendances multivariées, de vérifier la signification statistique des coefficients de régression obtenus. L'idéologie de la vérification est la même que lors de la vérification de l'équation dans son ensemble, mais en tant que critère, le critère de Student est utilisé, qui est déterminé par les formules :
 et
et 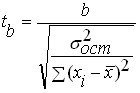
où: , - Valeurs des critères de Student pour les coefficients et respectivement;
 - variance résiduelle de l'équation de régression ;
- variance résiduelle de l'équation de régression ;
Nombre de points dans l'échantillon ;
Le nombre de variables dans l'échantillon, pour la régression linéaire par paires.
Les valeurs réelles obtenues du critère de Student sont comparées aux valeurs tabulaires ![]() obtenu à partir de la distribution de Student. S'il s'avère que , alors le coefficient correspondant est statistiquement significatif, sinon il ne l'est pas. La deuxième option pour vérifier la signification statistique des coefficients consiste à déterminer la probabilité d'occurrence du test t de Student et à comparer avec le niveau de signification .
obtenu à partir de la distribution de Student. S'il s'avère que , alors le coefficient correspondant est statistiquement significatif, sinon il ne l'est pas. La deuxième option pour vérifier la signification statistique des coefficients consiste à déterminer la probabilité d'occurrence du test t de Student et à comparer avec le niveau de signification .
Les variables dont les coefficients ne sont pas statistiquement significatifs sont susceptibles d'avoir aucun effet sur la variable dépendante dans la population. Par conséquent, soit il faut augmenter le nombre de points dans l'échantillon, alors il est possible que le coefficient devienne statistiquement significatif et en même temps sa valeur soit affinée, soit, en tant que variables indépendantes, en trouver d'autres plus proches lié à la variable dépendante. Dans ce cas, la précision des prévisions augmentera dans les deux cas.
Comme méthode expresse pour évaluer la signification des coefficients de l'équation de régression, on peut utiliser règle suivante- si le critère de Student est supérieur à 3, alors un tel coefficient, en règle générale, s'avère statistiquement significatif. En général, on pense que pour obtenir des équations de régression statistiquement significatives, il est nécessaire que la condition soit satisfaite.
L'erreur type de prévision selon l'équation de régression obtenue d'une valeur inconnue avec une valeur connue est estimée par la formule :

Ainsi, une prévision avec un niveau de confiance de 68 % peut être représentée comme suit :
Dans le cas où un autre un niveau de confiance, alors pour le seuil de signification il faut trouver le critère de Student et Intervalle de confiance pour une prévision dont le niveau de fiabilité sera égal à ![]() .
.
Prédiction des dépendances multidimensionnelles et non linéaires
Si la valeur prédite dépend de plusieurs variables indépendantes, alors dans ce cas il s'agit d'une régression multivariée de la forme :
où : - coefficients de régression décrivant l'influence des variables sur la valeur prédite.
La méthodologie de détermination des coefficients de régression n'est pas différente de la régression linéaire par paires, en particulier lors de l'utilisation d'une feuille de calcul, car la même fonction y est utilisée pour la régression linéaire par paires et multivariée. Dans ce cas, il est souhaitable qu'il n'y ait pas de relations entre les variables indépendantes, c'est-à-dire changer une variable n'affectait pas les valeurs des autres variables. Mais cette exigence n'est pas obligatoire, il est important qu'il n'y ait pas de dépendances linéaires fonctionnelles entre les variables. Les procédures ci-dessus pour vérifier la signification statistique de l'équation de régression obtenue et de ses coefficients individuels, l'évaluation de la précision de la prévision reste la même que pour le cas de la régression linéaire appariée. Dans le même temps, l'utilisation de régressions multivariées au lieu d'une régression par paires permet généralement, avec un choix approprié de variables, d'améliorer considérablement la précision de la description du comportement de la variable dépendante, et donc la précision de la prévision.
De plus, les équations de régression linéaire multivariée permettent de décrire la dépendance non linéaire de la valeur prédite à des variables indépendantes. Procédure de moulage équation non linéaireà forme linéaire est appelée linéarisation. En particulier, si cette dépendance est décrite par un polynôme de degré différent de 1, alors, en remplaçant les variables de degrés différents de l'unité par de nouvelles variables au premier degré, on obtient un problème de régression linéaire multivariée au lieu d'un problème non linéaire. Ainsi, par exemple, si l'influence de la variable indépendante est décrite par une parabole de la forme
![]()
alors le remplacement permet de transformer le problème non linéaire en un problème linéaire multidimensionnel de la forme
![]()
Les problèmes non linéaires peuvent être convertis tout aussi facilement, dans lesquels la non-linéarité se produit en raison du fait que la valeur prédite dépend du produit de variables indépendantes. Pour tenir compte de cet effet, il faut introduire une nouvelle variable égale à ce produit.
Dans les cas où la non-linéarité est décrite par des dépendances plus complexes, la linéarisation est possible grâce aux transformations de coordonnées. Pour cela, les valeurs sont calculées ![]() et des graphiques de la dépendance des points initiaux dans diverses combinaisons des variables transformées sont construits. Cette combinaison de coordonnées transformées, ou de coordonnées transformées et non transformées, dans laquelle la dépendance est la plus proche d'une ligne droite suggère un changement de variables qui conduira à une transformation non dépendance linéaireà une vue linéaire. Par exemple, une dépendance non linéaire de la forme
et des graphiques de la dépendance des points initiaux dans diverses combinaisons des variables transformées sont construits. Cette combinaison de coordonnées transformées, ou de coordonnées transformées et non transformées, dans laquelle la dépendance est la plus proche d'une ligne droite suggère un changement de variables qui conduira à une transformation non dépendance linéaireà une vue linéaire. Par exemple, une dépendance non linéaire de la forme
devient linéaire
Les coefficients de régression résultants pour l'équation transformée restent impartiaux et efficaces, mais l'équation et les coefficients ne peuvent pas être testés pour leur signification statistique
Vérification de la validité de l'application de la méthode moindres carrés
L'utilisation de la méthode des moindres carrés assure l'efficacité et l'impartialité des estimations des coefficients de l'équation de régression, sous réserve des conditions suivantes (conditions de Gaus-Markov) :
3. les valeurs ne dépendent pas les unes des autres
4. les valeurs ne dépendent pas de variables indépendantes
Le moyen le plus simple de vérifier si ces conditions sont remplies consiste à tracer les résidus en fonction de , puis la ou les variables indépendantes. Si les points sur ces graphiques sont situés dans un couloir situé symétriquement à l'axe des x et qu'il n'y a pas de régularité dans l'emplacement des points, alors les conditions de Gaus-Markov sont remplies et il n'y a aucune possibilité d'améliorer la précision de la régression équation. Si ce n'est pas le cas, il est alors possible d'améliorer considérablement la précision de l'équation, et pour cela, il est nécessaire de se référer à la littérature spécialisée.
Tests finaux en économétrie
1. L'appréciation de la significativité des paramètres de l'équation de régression s'effectue sur la base de :
A) t - Critère de Student ;
b) critère F de Fisher - Snedekor ;
c) erreur quadratique moyenne ;
d) erreur d'approximation moyenne.
2. Le coefficient de régression dans l'équation caractérisant la relation entre le volume des ventes (millions de roubles) et le bénéfice des entreprises de l'industrie automobile pour l'année (millions de roubles) signifie qu'avec une augmentation du volume des ventes de 1 millions de roubles le bénéfice augmente de :
d) 0,5 million frotter.;
c) 500 mille. frotter.;
D) 1,5 million de roubles
3. Le rapport de corrélation (indice de corrélation) mesure le degré de proximité de la relation entre X etOui:
a) uniquement avec une forme de dépendance non linéaire ;
B) avec toute forme de dépendance ;
c) seulement avec une relation linéaire.
4. Dans le sens de la communication, il y a:
a) modéré ;
B) droit ;
c) rectiligne.
5. Sur la base de 17 observations, une équation de régression a été construite :  .
Pour vérifier la signification de l'équation, nous avons calculévaleur observéet- statistiques : 3.9. Conclusion:
.
Pour vérifier la signification de l'équation, nous avons calculévaleur observéet- statistiques : 3.9. Conclusion:
A) L'équation est significative pour un = 0,05;
b) L'équation est non significative à a = 0,01 ;
c) L'équation n'est pas significative à a = 0,05.
6. Quelles sont les conséquences de la violation de l'hypothèse MCO « l'espérance des résidus de régression est nulle » ?
A) Estimations biaisées des coefficients de régression ;
b) Estimations efficaces mais incohérentes des coefficients de régression ;
c) Estimations inefficaces des coefficients de régression ;
d) Estimations incohérentes des coefficients de régression.
7. Lequel des énoncés suivants est vrai en cas d'hétéroscédasticité des résidus ?
A) Les conclusions sur les statistiques t et F ne sont pas fiables ;
d) Les estimations des paramètres de l'équation de régression sont biaisées.
8. Sur quoi est basé le test ? corrélation de rang Lancier?
A) Sur l'utilisation des statistiques t ;
c) Lors de l'utilisation  ;
;
9. Sur quoi est basé le test de White ?
b) Sur l'utilisation des statistiques F ;
B) en cours d'utilisation  ;
;
d) Sur l'analyse graphique des résidus.
10. Quelle méthode peut être utilisée pour éliminer l'autocorrélation ?
11. Comment appelle-t-on la violation de l'hypothèse de constance de la variance des résidus ?
a) multicolinéarité ;
b) Autocorrélation ;
B) Hétéroscédasticité ;
d) Homoscédasticité.
12. Des variables indicatrices sont introduites dans :
a) uniquement dans les modèles linéaires ;
b) uniquement en régression non linéaire multiple ;
c) uniquement dans les modèles non linéaires ;
D) des modèles linéaires et non linéaires réduits à une forme linéaire.
13. Si dans la matrice des coefficients de corrélation appariés il y a  , alors cela montre:
, alors cela montre:
A) A propos de la présence de multicolinéarité ;
b) A propos de l'absence de multicolinéarité ;
c) A propos de la présence d'autocorrélation ;
d) De l'absence d'hétéroscédasticité.
14. Quelle mesure est impossible de se débarrasser de la multicolinéarité ?
a) Augmenter la taille de l'échantillon ;
D) Transformation de la composante aléatoire.
15. Si  et le rang de la matrice A est inférieur à (K-1) alors l'équation :
et le rang de la matrice A est inférieur à (K-1) alors l'équation :
a) sur-identifié ;
B) non identifié ;
c) identifié avec précision.
16. L'équation de régression ressemble à :
MAIS)  ;
;
b)  ;
;
dans)  .
.
17. Quel est le problème de l'identification du modèle ?
A) obtenir des paramètres définis de manière unique du modèle donné par le système d'équations simultanées ;
b) sélection et mise en œuvre de méthodes d'estimation statistique de paramètres inconnus du modèle en fonction des données statistiques initiales ;
c) vérifier l'adéquation du modèle.
18. Quelle méthode est utilisée pour estimer les paramètres d'une équation sur-identifiée ?
C) DMNK, KMNK ;
19. Si une variable qualitative akvaleurs alternatives, la simulation utilise :
A) (k-1) variable fictive ;
b) kvariables fictives ;
c) (k+1) variable fictive.
20. L'analyse de la proximité et de la direction des liens de deux signes est effectuée sur la base de:
A) coefficient de corrélation de paire ;
b) coefficient de détermination ;
c) coefficient de corrélation multiple.
21. Dans une équation linéaire
 X =
un 0
+ un 1
x coefficient de régression indique :
X =
un 0
+ un 1
x coefficient de régression indique :
a) la proximité de la connexion ;
b) proportion de la variance "Y" dépendante de "X" ;
C) de combien "Y" changera en moyenne lorsque "X" changera d'une unité ;
d) erreur de coefficient de corrélation.
22. Quel indicateur est utilisé pour déterminer la part de la variation due à un changement de la valeur du facteur à l'étude ?
a) coefficient de variation ;
b) coefficient de corrélation ;
C) coefficient de détermination ;
d) coefficient d'élasticité.
23. Le coefficient d'élasticité indique :
A) de quel % la valeur de y changera-t-elle lorsque x changera de 1 % ;
b) de combien d'unités de sa mesure la valeur de y changera-t-elle lorsque x changera de 1 % ;
c) de combien de % la valeur de y changera-t-elle lorsque x changera d'unité. votre mesure.
24. Quelles méthodes peuvent être appliquées pour détecter l'hétéroscédasticité?
A) Test de Golfeld-Quandt ;
B) test de corrélation de rang de Spearman ;
c) Test de Durbin-Watson.
25. Quelle est la base du test de Golfeld-Quandt
a) Sur l'utilisation des statistiques t ;
B) Sur l'utilisation de F - statistiques ;
c) Lors de l'utilisation  ;
;
d) Sur l'analyse graphique des résidus.
26. Quelles méthodes ne peuvent pas être utilisées pour éliminer l'autocorrélation des résidus ?
a) Méthode généralisée des moindres carrés ;
B) Méthode des moindres carrés pondérés ;
C) la méthode du maximum de vraisemblance ;
D) Méthode des moindres carrés en deux étapes.
27. Comment appelle-t-on la violation de l'hypothèse d'indépendance des résidus ?
a) multicolinéarité ;
B) Autocorrélation ;
c) Hétéroscédasticité ;
d) Homoscédasticité.
28. Quelle méthode peut être utilisée pour éliminer l'hétéroscédasticité ?
A) Méthode généralisée des moindres carrés ;
b) Méthode des moindres carrés pondérés ;
c) La méthode du maximum de vraisemblance ;
d) Méthode des moindres carrés en deux étapes.
30. Si part-critère, la plupart des coefficients de régression sont statistiquement significatifs, et le modèle dans son ensembleF- le critère est non significatif, alors cela peut indiquer :
a) multicolinéarité ;
B) Sur l'autocorrélation des résidus ;
c) Sur l'hétéroscédasticité des résidus ;
d) Cette option n'est pas possible.
31. Est-il possible de se débarrasser de la multicolinéarité en transformant des variables ?
a) Cette mesure n'est efficace que lorsque la taille de l'échantillon est augmentée ;
32. Quelle méthode peut être utilisée pour trouver des estimations du paramètre de l'équation de régression linéaire :
A) la méthode des moindres carrés ;
b) corrélation- analyse de régression;
c) analyse de variance.
33. Une équation de régression linéaire multiple avec des variables fictives est construite. Pour vérifier la signification des coefficients individuels, nous utilisons Distribution:
a) normale ;
b) Étudiant ;
c) Person ;
d) Fischer-Snedekor.
34. Si  et le rang de la matrice A est supérieur à (K-1) alors l'équation :
et le rang de la matrice A est supérieur à (K-1) alors l'équation :
A) sur-identifié ;
b) non identifié ;
c) identifié avec précision.
35. Pour estimer les paramètres d'un système d'équations précisément identifiable, on utilise :
a) DMNK, KMNK ;
b) DMNK, MNK, KMNK ;
36. Le critère de Chow est basé sur l'application de :
A) F - statistiques ;
b) t - statistiques ;
c) Critères de Durbin-Watson.
37. Les variables muettes peuvent prendre les valeurs suivantes :
d) toutes les valeurs.
39. Sur la base de 20 observations, une équation de régression a été construite :  .
Pour vérifier la signification de l'équation, la valeur de la statistique est calculée :4.2. Conclusion :
.
Pour vérifier la signification de l'équation, la valeur de la statistique est calculée :4.2. Conclusion :
a) L'équation est significative à a=0,05 ;
b) L'équation n'est pas significative à a=0,05 ;
c) L'équation n'est pas significative à a=0,01.
40. Lequel des énoncés suivants n'est pas vrai si les résidus sont hétéroscédastiques ?
a) Les conclusions sur les statistiques t et F ne sont pas fiables ;
b) L'hétéroscédasticité se manifeste par la faible valeur de la statistique de Durbin-Watson ;
c) Avec l'hétéroscédasticité, les estimations restent efficaces ;
d) Les estimations sont biaisées.
41. Le test de Chow est basé sur une comparaison :
A) dispersions ;
b) coefficients de détermination ;
c) attentes mathématiques;
d) moyen.
42. Si dans le test de Chow  alors on considère :
alors on considère :
A) que le partitionnement en sous-intervalles est utile du point de vue de l'amélioration de la qualité du modèle ;
b) le modèle est statistiquement non significatif ;
c) le modèle est statistiquement significatif ;
d) qu'il n'est pas logique de diviser l'échantillon en parties.
43. Les variables muettes sont des variables :
une qualité;
b) aléatoire ;
B) quantitatif ;
d) logique.
44. Laquelle des méthodes suivantes ne peut pas être utilisée pour détecter l'autocorrélation ?
a) méthode des séries ;
b) test de Durbin-Watson ;
c) test de corrélation des rangs de Spearman ;
D) Le test de White.
45. La forme structurelle la plus simple du modèle est la suivante :
MAIS) 
b) 
dans) 
G)  .
.
46. Quelles mesures peut-on prendre pour se débarrasser de la multicolinéarité ?
a) Augmenter la taille de l'échantillon ;
b) Exclusion des variables fortement corrélées au reste ;
c) Modification de la spécification du modèle ;
d) Transformation de la composante aléatoire.
47. Si  et le rang de la matrice A est (K-1) alors l'équation :
et le rang de la matrice A est (K-1) alors l'équation :
a) sur-identifié ;
b) non identifié ;
B) identifié avec précision ;
48. Un modèle est considéré identifié si :
a) parmi les équations du modèle, il y en a au moins une normale ;
B) chaque équation du système est identifiable ;
c) parmi les équations modèles il y en a au moins une non identifiée ;
d) parmi les équations du modèle il y en a au moins une suridentifiée.
49. Quelle méthode est utilisée pour estimer les paramètres d'une équation non identifiée ?
a) DMNK, KMNK ;
b) DMNC, MNC ;
C) les paramètres d'une telle équation ne peuvent pas être estimés.
50. À la jonction de quels domaines de la connaissance l'économétrie est-elle apparue :
A) théorie économique; économique et statistiques mathématiques;
b) théorie économique, statistique mathématique et théorie des probabilités ;
c) statistiques économiques et mathématiques, théorie des probabilités.
51. Dans l'équation de régression linéaire multiple, des intervalles de confiance sont construits pour les coefficients de régression en utilisant la distribution :
a) normale ;
B) Étudiant ;
c) Person ;
d) Fischer-Snedekor.
52. Sur la base de 16 observations, une équation de régression linéaire appariée a été construite. Pourvérification de la signification du coefficient de régression calculéet pour 6l =2.5.
a) Le coefficient est non significatif à a=0,05 ;
b) Le coefficient est significatif à a=0,05 ;
c) Le coefficient est significatif à a=0,01.
53. On sait qu'entre les quantitésXetOuiexisteconnexion positive. Dans quelle mesureest le coefficient de corrélation par paires ?
a) de -1 à 0 ;
b) de 0 à 1 ;
C) de -1 à 1.
54. Le coefficient de corrélation multiple est de 0,9. Quel pourcentagedispersion de l'attribut résultant s'explique par l'influence de touscaractéristiques factorielles ?
55. Laquelle des méthodes suivantes ne peut pas être utilisée pour détecter l'hétéroscédasticité?
A) Test de Golfeld-Quandt ;
b) test de corrélation des rangs de Spearman ;
c) méthode des séries.
56. La forme donnée du modèle est :
a) un système de fonctions non linéaires de variables exogènes à partir de variables endogènes ;
B) système fonctions linéaires variables endogènes à partir d'exogènes ;
c) un système de fonctions linéaires de variables exogènes à partir de variables endogènes ;
d) un système d'équations normales.
57. Dans quelles limites le coefficient de corrélation partielle calculé par les formules récursives évolue-t-il ?
a) de -  à +
à +  ;
;
b) de 0 à 1 ;
c) de 0 à +  ;
;
D) de -1 à +1.
58. Dans quelles limites le coefficient de corrélation partielle calculé par le coefficient de détermination évolue-t-il ?
a) de -  à +
à +  ;
;
B) de 0 à 1 ;
c) de 0 à +  ;
;
d) de –1 à +1.
59. Variables exogènes :
a) variables dépendantes ;
B) variables indépendantes ;
61. Lorsqu'on ajoute un autre facteur explicatif à l'équation de régression, le coefficient de corrélation multiple :
a) diminuera
b) augmentera ;
c) conserver sa valeur.
62. Une équation de régression hyperbolique a été construite :Oui= un+ b/ X. PourLe test de signification de l'équation utilise la distribution :
a) normale ;
B) Étudiant ;
c) Person ;
d) Fischer-Snedekor.
63. Pour quels types de systèmes les paramètres des équations économétriques individuelles peuvent-ils être trouvés en utilisant la méthode traditionnelle des moindres carrés ?
a) un système d'équations normales ;
B) un système d'équations indépendantes ;
C) un système d'équations récursives ;
D) un système d'équations interdépendantes.
64. Variables endogènes :
A) variables dépendantes ;
b) variables indépendantes ;
c) daté de points antérieurs dans le temps.
65. Dans quelles limites le coefficient de détermination change-t-il ?
a) de 0 à +  ;
;
b) de -  à +
à +  ;
;
C) de 0 à +1 ;
d) de -l à +1.
66. Une équation de régression linéaire multiple a été construite. Pour vérifier la signification des coefficients individuels, nous utilisons Distribution:
a) normale ;
b) Étudiant ;
c) Person ;
D) Fischer-Snedekor.
67. Lorsqu'on ajoute un autre facteur explicatif à l'équation de régression, le coefficient de détermination :
a) diminuera
B) augmentera ;
c) conserver sa valeur ;
d) ne diminuera pas.
68. L'essence de la méthode des moindres carrés est la suivante :
A) l'estimation est déterminée à partir de la condition de minimisation de la somme des écarts au carré des données d'échantillon par rapport à l'estimation déterminée ;
b) l'estimation est déterminée à partir de la condition de minimisation de la somme des écarts des données d'échantillon par rapport à l'estimation déterminée ;
c) l'estimation est déterminée à partir de la condition de minimisation de la somme des écarts au carré de la moyenne de l'échantillon par rapport à la variance de l'échantillon.
69. À quelle classe de régressions non linéaires appartient la parabole :
73. À quelle classe de régressions non linéaires appartient la courbe exponentielle :
74. À quelle classe de régressions non linéaires une fonction de la forme ŷ appartient-elle  :
:
A) des régressions non linéaires par rapport aux variables incluses dans l'analyse, mais linéaires par rapport aux paramètres estimés ;
b) des régressions non linéaires sur les paramètres estimés.
78. À quelle classe de régressions non linéaires une fonction de la forme ŷ appartient-elle  :
:
a) des régressions non linéaires par rapport aux variables incluses dans l'analyse, mais linéaires par rapport aux paramètres estimés ;
B) régressions non linéaires sur les paramètres estimés.
79. Dans l'équation de régression sous la forme d'une hyperbole ŷ  si la valeurb
>0
, alors:
si la valeurb
>0
, alors:
A) avec une augmentation du trait factoriel X la valeur de l'attribut résultant à diminuer lentement, et x→∞ valeur moyenne à sera égal à un;
b) la valeur de la caractéristique efficace à augmente avec une croissance lente avec une augmentation du trait factoriel X, et à x→∞

81. Le coefficient d'élasticité est déterminé par la formule 
A) Fonction linéaire ;
b) Paraboles ;
c) Hyperboles ;
d) courbe exponentielle ;
e) Puissance.
82. Le coefficient d'élasticité est déterminé par la formule  pour un modèle de régression sous la forme :
pour un modèle de régression sous la forme :
a) Fonction linéaire ;
B) Paraboles ;
c) Hyperboles ;
d) courbe exponentielle ;
e) Puissance.
86. Équation  appelé:
appelé:
A) une tendance linéaire
b) tendance parabolique ;
c) tendance hyperbolique ;
d) tendance exponentielle.
89. Équation  appelé:
appelé:
a) une tendance linéaire ;
b) tendance parabolique ;
c) tendance hyperbolique ;
D) une tendance exponentielle.
90. Vues système
 appelé:
appelé:
A) un système d'équations indépendantes ;
b) un système d'équations récursives ;
c) un système d'équations interdépendantes (simultanées, simultanées).
93. L'économétrie peut être définie comme :
A) c'est une discipline scientifique indépendante qui combine un ensemble de résultats théoriques, de techniques, de méthodes et de modèles conçus pour donner une expression quantitative spécifique aux schémas généraux (qualitatifs) dus à la théorie économique sur la base de la théorie économique, des statistiques économiques et des mathématiques et outils statistiques;
B) la science des mesures économiques ;
C) analyse statistique des données économiques.
94. Les tâches de l'économétrie comprennent :
A) prévision des indicateurs économiques et socio-économiques caractérisant l'état et l'évolution du système analysé ;
B) simulation de scénarios possibles pour le développement socio-économique du système afin d'identifier comment les changements prévus de certains paramètres gérables affecteront les caractéristiques de sortie ;
c) test d'hypothèses en fonction de données statistiques.
95. Les relations se distinguent par leur nature :
A) fonctionnel et corrélation ;
b) fonctionnel, curviligne et rectiligne ;
c) corrélation et inverse ;
d) statistique et directe.
96. En lien direct avec une augmentation d'un trait factoriel :
a) le signe effectif diminue ;
b) l'attribut effectif ne change pas ;
C) l'indicateur de performance augmente.
97. Quelles méthodes sont utilisées pour identifier la présence, la nature et la direction de l'association dans les statistiques ?
a) valeurs moyennes ;
B) comparaison de rangées parallèles ;
C) méthode de regroupement analytique ;
d) valeurs relatives ;
D) méthode graphique.
98. Quelle méthode est utilisée pour identifier les formes d'influence de certains facteurs sur d'autres ?
a) analyse de corrélation ;
B) analyse de régression ;
c) analyse d'indices ;
d) analyse de variance.
99. Quelle méthode est utilisée pour quantifier la force de l'impact de certains facteurs sur d'autres :
A) analyse de corrélation ;
b) analyse de régression ;
c) la méthode des moyennes ;
d) analyse de variance.
100. Quels indicateurs dans leur ampleur existent dans la gamme de moins à plus un:
a) coefficient de détermination ;
b) rapport de corrélation ;
C) coefficient de corrélation linéaire.
101. Le coefficient de régression pour un modèle à un facteur indique :
A) combien d'unités la fonction change lorsque l'argument change d'une unité ;
b) de combien de pourcentage la fonction change par unité de changement dans l'argument.
102. Le coefficient d'élasticité indique :
a) de combien de pourcentage la fonction change-t-elle avec un changement d'argument d'une unité de sa mesure ;
B) de combien de pour cent la fonction change-t-elle avec une modification de l'argument de 1 % ;
c) de combien d'unités de sa mesure la fonction change avec une modification de l'argument de 1%.
105. La valeur de l'indice de corrélation, égale à 0,087, indique :
A) sur leur faible dépendance ;
b) une relation solide;
c) erreurs de calcul.
107. La valeur du coefficient de corrélation du couple, égale à 1,12, indique :
a) sur leur faible dépendance ;
b) une relation solide;
C) sur les erreurs de calcul.
109. Lequel des nombres donnés peut être les valeurs du coefficient de corrélation de paire:
111. Lequel des nombres donnés peut être les valeurs du coefficient de corrélation multiple :
115. Marquez la forme correcte de l'équation de régression linéaire :
comme  ;
;
par  ;
;
c) ŷ  ;
;
D) ŷ  .
.
Pour vérifier la significativité, le rapport du coefficient de régression et de son écart type est analysé. Ce rapport est une distribution de Student, c'est-à-dire que pour déterminer la signification, nous utilisons le critère t :
 - OSK de la dispersion résiduelle ;
- OSK de la dispersion résiduelle ;
 - somme des écarts par rapport à la valeur moyenne
- somme des écarts par rapport à la valeur moyenne
Si t courses. >t onglet. , alors le coefficient b i est significatif.
L'intervalle de confiance est déterminé par la formule :
PROCÉDURE DE TRAVAIL
Prendre les données initiales selon la variante du travail (selon le numéro de l'élève dans le journal). Un objet de contrôle statique avec deux entrées est spécifié X 1 , X 2 et une sortie Oui. Une expérience passive a été réalisée sur l'objet et un échantillon de 30 points a été obtenu contenant les valeurs X 1 , X 2 et Oui pour chaque expérience.
Ouvrez un nouveau fichier dans Excel 2007. Entrez Informations d'arrière-plan dans les colonnes de la table source - les valeurs des variables d'entrée X 1 , X 2 et variable de sortie Oui.
Préparez deux colonnes supplémentaires pour saisir les valeurs calculées Oui et les restes.
Appelez le programme "Régression": Données / Analyse de données / Régression.

Riz. 1. Boîte de dialogue "Analyse des données".
Saisissez dans la boîte de dialogue "Régression" les adresses des données sources :
intervalle d'entrée Y, intervalle d'entrée X (2 colonnes),
régler le niveau de fiabilité à 95%,
dans l'option "Intervalle de sortie, spécifiez la cellule supérieure gauche de l'endroit où les données d'analyse de régression sont sorties (la première cellule de la feuille de calcul de 2 pages),
activer les options "Remains" et "Graph of Remains",
appuyez sur le bouton OK pour démarrer l'analyse de régression.

Riz. 2. Boîte de dialogue "Régression".
Excel affichera 4 tableaux et 2 graphiques de résidus par rapport aux variables X1 et X2.
Formatez le tableau "Sortie des totaux" - développez la colonne avec les noms des données de sortie, faites 3 chiffres significatifs après la virgule décimale dans la deuxième colonne.
Formater le tableau " Analyse de variance»- faciliter la lecture et la compréhension du nombre de chiffres significatifs après les virgules, raccourcir les noms des variables et ajuster la largeur des colonnes.
Mettre en forme le tableau des coefficients de l'équation - raccourcir les noms des variables et ajuster la largeur des colonnes si nécessaire, rendre le nombre de chiffres significatifs pratique pour la lecture et la compréhension, supprimer les 2 dernières colonnes (valeurs et tableau balisage).
Transférez les données de la table "Remainder Output" vers les colonnes préparées de la table source, puis supprimez la table "Remainder Output" (option "Special Insert").
Entrez les estimations résultantes des coefficients dans le tableau d'origine.
Tirez les tableaux de résultats vers le haut de la page autant que possible.
Créer des graphiques sous les tableaux Ouiexp, Ouicalc et les erreurs de prévision (résiduelles).
Mettre en forme les graphiques résiduels. Sur la base des graphiques obtenus, évaluez l'exactitude du modèle par les entrées X1, X2.
Imprimer les résultats de l'analyse de régression.
Traiter les résultats de l'analyse de régression.
Préparer un rapport de travail.
EXEMPLE DE TRAVAIL
La méthode d'exécution de l'analyse de régression dans le package EXCEL est illustrée dans les figures 3-5.

Riz. 3. Un exemple d'analyse de régression dans le package EXCEL.


Fig.4. Parcelles de résidus variables X1, X2

Riz. 5. Graphiques Ouiexp,Ouicalc et les erreurs de prévision (résiduelles).
D'après l'analyse de régression, on peut dire :
1. L'équation de régression obtenue à l'aide d'Excel a la forme :
Coefficient de détermination :

La variation du résultat de 46,5% s'explique par la variation des facteurs.
Le test F général teste l'hypothèse sur la signification statistique de l'équation de régression. L'analyse est effectuée en comparant les valeurs réelles et tabulaires du test F de Fisher.

Étant donné que la valeur réelle dépasse la table  , nous concluons que l'équation de régression résultante est statistiquement significative.
, nous concluons que l'équation de régression résultante est statistiquement significative.
Coefficient corrélation multiple:
b 0 :
t onglet. (29, 0,975)=2,05
b 0 :
![]()
Intervalle de confiance:
Déterminer l'intervalle de confiance pour le coefficient b 1 :
Vérification de l'importance du coefficient b 1 :
![]()
traces >t onglet. , le coefficient b 1 est significatif
Intervalle de confiance:
Déterminer l'intervalle de confiance pour le coefficient b 2 :
Test de signification pour le coefficient b 2 :
![]()
Déterminez l'intervalle de confiance :
OPTIONS D'AFFECTATION
Tableau 2. Options de tâche
|
numéro d'option | |||||||||||||||
|
Signe efficace Oui je |
Oui 1 |
Oui 1 |
Oui 1 |
Oui 1 |
Oui 1 |
Oui 1 |
Oui 1 |
Oui 1 |
Oui 1 |
Oui 1 |
Oui 2 |
Oui 2 |
Oui 2 |
Oui 2 |
Oui 2 |
|
numéro de facteur X je | |||||||||||||||
|
numéro de facteur X je |
Tableau 1 suite
|
numéro d'option | |||||||||||||||
|
Signe efficace Oui je |
Oui 2 |
Oui 2 |
Oui 2 |
Oui 2 |
Oui 2 |
Oui 3 |
Oui 3 |
Oui 3 |
Oui 3 |
Oui 3 |
Oui 3 |
Oui 3 |
Oui 3 |
Oui 3 |
Oui 3 |
|
numéro de facteur X je | |||||||||||||||
|
numéro de facteur X je |
Tableau 3. Données initiales
|
Oui 1 |
Oui 2 |
Oui 3 |
X 1 |
X 2 |
X 3 |
X 4 |
X 5 |
|
QUESTIONS POUR L'AUTO-VÉRIFICATION
Problèmes d'analyse de régression.
Prérequis pour l'analyse de régression.
Équation de base de l'analyse de dispersion.
Que montre le rapport F de Fisher ?
Comment la valeur tabulaire du critère de Fisher est-elle déterminée ?
Que montre le coefficient de détermination ?
Comment déterminer la significativité des coefficients de régression ?
Comment déterminer l'intervalle de confiance des coefficients de régression ?
Comment déterminer la valeur calculée du test t ?
Comment déterminer la valeur tabulaire du test t ?
Formuler l'idée principale de l'analyse de variance, pour quelles tâches est-elle la plus efficace ?
Quelles sont les principales prémisses théoriques de l'analyse de la variance ?
Décomposer la somme totale des écarts au carré en composantes dans l'analyse de la variance.
Comment obtenir des estimations de variance à partir de sommes d'écarts au carré ?
Comment les degrés de liberté requis sont-ils obtenus ?
Comment l'erreur standard est-elle déterminée ?
Expliquez le schéma de l'analyse de variance à deux facteurs.
En quoi la classification croisée diffère-t-elle de la classification hiérarchique ?
En quoi les données équilibrées sont-elles différentes ?
Le rapport est rédigé dans un éditeur de texte Word sur papier A4 GOST 6656-76 (210x297 mm) et contient :
Résultats des calculs.
Nom du laboratoire.
Objectif.
TEMPS AUTORISÉ POUR LA RÉALISATION
TRAVAIL EN LABORATOIRE
Préparation au travail - 0,5 acad. heures.
Performance des travaux - 0,5 acad. heures.
Calculs informatiques - 0,5 acad. heures.
Enregistrement du travail - 0,5 acad. heures.
Littérature
Identification des objets de contrôle. / A. D. Semenov, D. V. Artamonov, A. V. Bryukhachev. Didacticiel. - Penza : PGU, 2003. - 211 p.
Bases analyses statistiques. Atelier sur Méthodes statistiques et la recherche opérationnelle à l'aide des progiciels STATISTIC et EXCEL. / Vukolov E.A. Didacticiel. - M. : FORUM, 2008. - 464 p.
Principes fondamentaux de la théorie de l'identification des objets de contrôle. / A.A. Ignatiev, S.A. Ignatiev. Didacticiel. - Saratov : SGTU, 2008. - 44 p.
Théorie des probabilités et statistiques mathématiques dans des exemples et des tâches utilisant EXCEL. / G.V. Gorelova, IA Katsko. - Rostov n/a : Phoenix, 2006. - 475 p.
Retirons C = 1/4 n = 1/4 50 = 12,5 (12) valeurs du milieu de l'ensemble ordonné. En conséquence, nous obtenons deux populations, respectivement, avec de petites et grandes valeurs de X4.
Pour chaque ensemble, nous effectuons les calculs :
But du travail 2
Notions de base 2
Ordre de travail 6
Exemple de travail 9
Questions pour la maîtrise de soi 13
Temps alloué au travail 14
Après évaluation des paramètres un et b, nous avons obtenu une équation de régression par laquelle nous pouvons estimer les valeurs y par valeurs définies X. Il est naturel de supposer que les valeurs calculées de la variable dépendante ne coïncideront pas avec les valeurs réelles, car la droite de régression ne décrit la relation qu'en moyenne, en général. Des significations distinctes sont éparpillées autour de lui. Ainsi, la fiabilité des valeurs calculées obtenues à partir de l'équation de régression est largement déterminée par la dispersion des valeurs observées autour de la droite de régression. En pratique, en règle générale, la variance d'erreur est inconnue et est estimée à partir des observations simultanément avec les paramètres de régression. un et b. Il est tout à fait logique de supposer que l'estimation est liée à la somme des carrés des résidus de régression. La quantité est un exemple d'estimation de la variance des perturbations contenues dans modèle théorique ![]() . On peut montrer que pour un modèle de régression apparié
. On peut montrer que pour un modèle de régression apparié
où est l'écart entre la valeur réelle de la variable dépendante et sa valeur calculée.
Si un ![]() , alors pour toutes les observations, les valeurs réelles de la variable dépendante coïncident avec les valeurs calculées (théoriques) .
Graphiquement, cela signifie que la droite de régression théorique (la droite construite à partir de la fonction ) passe par tous les points du champ de corrélation, ce qui n'est possible qu'avec une connexion strictement fonctionnelle. Par conséquent, le signe effectif à complètement en raison de l'influence du facteur X.
, alors pour toutes les observations, les valeurs réelles de la variable dépendante coïncident avec les valeurs calculées (théoriques) .
Graphiquement, cela signifie que la droite de régression théorique (la droite construite à partir de la fonction ) passe par tous les points du champ de corrélation, ce qui n'est possible qu'avec une connexion strictement fonctionnelle. Par conséquent, le signe effectif à complètement en raison de l'influence du facteur X.
Habituellement, en pratique, il existe une certaine dispersion des points du champ de corrélation par rapport à la ligne de régression théorique, c'est-à-dire des écarts entre les données empiriques et les données théoriques. Cette dispersion est due à la fois à l'influence du facteur X, c'est à dire. régression y sur X, (une telle variance est dite expliquée, puisqu'elle est expliquée par l'équation de régression), et l'action d'autres causes (variation inexpliquée, aléatoire). L'ampleur de ces écarts sous-tend le calcul des indicateurs de qualité de l'équation.
Selon le principe de base de l'analyse de la variance, la somme totale des écarts au carré de la variable dépendante y de la valeur moyenne peut être décomposée en deux composantes : expliquée par l'équation de régression et inexpliquée :
 ,
,
où - valeurs y, calculé par l'équation .
Trouvons le rapport de la somme des écarts au carré, expliquée par l'équation de régression, à la somme totale des carrés :
 , où
, où
 . (7.6)
. (7.6)
Le rapport de la part de la variance expliquée par l'équation de régression à écart total l'attribut résultant est appelé le coefficient de détermination. La valeur ne peut pas dépasser un et cela valeur maximum ne sera atteint qu'à , c'est-à-dire lorsque chaque écart est égal à zéro et que, par conséquent, tous les points du nuage de points se trouvent exactement sur une ligne droite.
Le coefficient de détermination caractérise la part de la variance expliquée par la régression dans la valeur totale de la variance de la variable dépendante . En conséquence, la valeur caractérise la proportion de variation (dispersion) y, inexpliquée par l'équation de régression, et donc causée par l'influence d'autres facteurs non pris en compte dans le modèle. Plus on se rapproche de un, plus la qualité du modèle est élevée.
Avec la régression linéaire appariée, le coefficient de détermination est égal au carré de la coefficient linéaire corrélations : .
La racine de ce coefficient de détermination est le coefficient (indice) de corrélation multiple, ou le rapport de corrélation théorique.
Afin de savoir si la valeur du coefficient de détermination obtenue lors de l'évaluation de la régression reflète bien la véritable relation entre y et X vérifier la signification de l'équation construite dans son ensemble et paramètres individuels. Le test de signification de l'équation de régression vous permet de savoir si l'équation de régression convient à utilisation pratique, par exemple, prévoir ou non.
Dans le même temps, l'hypothèse principale est émise sur l'insignifiance de l'équation dans son ensemble, ce qui se réduit formellement à l'hypothèse que les paramètres de régression sont égaux à zéro, ou, ce qui revient au même, que le coefficient de détermination est égal à zéro : . Une hypothèse alternative sur la significativité de l'équation est l'hypothèse que les paramètres de régression ne sont pas égaux à zéro ou que le coefficient de détermination n'est pas égal à zéro : .
Pour tester la signification du modèle de régression, utilisez F- Critère de Fisher, calculé comme le rapport de la somme des carrés (pour une variable indépendante) à la somme résiduelle des carrés (pour un degré de liberté) :
 , (7.7)
, (7.7)
où k est le nombre de variables indépendantes.
Après avoir divisé le numérateur et le dénominateur de la relation (7.7) par la somme totale des écarts au carré de la variable dépendante, F- Le critère peut être exprimé de manière équivalente en termes de coefficient :
 .
.
Si l'hypothèse nulle est vraie, alors la variance expliquée par l'équation de régression et la variance inexpliquée (résiduelle) ne diffèrent pas l'une de l'autre.
Valeur estimée F- le critère est comparé à une valeur critique qui dépend du nombre de variables indépendantes k, et sur le nombre de degrés de liberté (n-k-1). Valeur (critique) du tableau F- critère - il s'agit de la valeur maximale du rapport des variances, qui peut se produire si elles divergent au hasard pour un niveau de probabilité donné de la présence d'une hypothèse nulle. Si la valeur calculée F- le critère est supérieur au critère tabulaire à un niveau de signification donné, alors l'hypothèse nulle sur l'absence de lien est rejetée et une conclusion est tirée sur la signification de ce lien, c'est-à-dire modèle est considéré comme significatif.
Pour un modèle de régression appariée
 .
.
Dans la régression linéaire, la signification non seulement de l'équation dans son ensemble, mais aussi de ses coefficients individuels est généralement estimée. Pour ce faire, l'erreur standard de chacun des paramètres est déterminée. Erreurs types les coefficients de régression des paramètres sont déterminés par les formules :
 , (7.8)
, (7.8)
 (7.9)
(7.9)
Les erreurs types des coefficients de régression ou des écarts types calculés par les formules (7.8,7.9), en règle générale, sont données dans les résultats du calcul du modèle de régression dans les progiciels statistiques.
Sur la base des erreurs types des coefficients de régression, la significativité de ces coefficients est vérifiée à l'aide de le schéma habituel test d'hypothèses statistiques.
Comme hypothèse principale, une hypothèse est avancée sur une différence non significative par rapport à zéro du "vrai" coefficient de régression. Une hypothèse alternative dans ce cas est l'hypothèse inverse, c'est-à-dire sur l'inégalité du "vrai" paramètre de régression à zéro. Cette hypothèse est testée à l'aide t- des statistiques qui ont t-Répartition étudiante :
Ensuite, les valeurs calculées t- les statistiques sont comparées aux valeurs critiques t- statistiques déterminées à partir des tables de distribution de Student. La valeur critique est déterminée en fonction du niveau de signification α et le nombre de degrés de liberté, qui est (n-k-1), n - nombre d'observations k- nombre de variables indépendantes. Dans le cas de la régression linéaire par paires, le nombre de degrés de liberté est (P- 2). La valeur critique peut également être calculée sur un ordinateur à l'aide de la fonction STUDISP intégrée d'Excel.
Si la valeur calculée t- les statistiques sont supérieures au critique, alors l'hypothèse principale est rejetée et on pense qu'avec une probabilité (1-a) Le "vrai" coefficient de régression est significativement différent de zéro, ce qui est une confirmation statistique de l'existence d'une relation linéaire entre les variables correspondantes.
Si la valeur calculée t- statistique est moins que critique, alors il n'y a aucune raison de rejeter l'hypothèse principale, c'est-à-dire que le "vrai" coefficient de régression n'est pas significativement différent de zéro au niveau de signification α . Dans ce cas, le facteur correspondant à ce coefficient doit être exclu du modèle.
La signification du coefficient de régression peut être établie en construisant un intervalle de confiance. Intervalle de confiance pour les paramètres de régression un et b défini comme suit :
![]() ,
,
![]() ,
,
où est déterminé à partir du tableau de distribution de Student pour le niveau de signification α et nombre de degrés de liberté (P- 2) pour la régression par paires.
Étant donné que les coefficients de régression dans les études économétriques ont une interprétation économique claire, les intervalles de confiance ne doivent pas contenir de zéro. La vraie valeur du coefficient de régression ne peut pas contenir simultanément des valeurs positives et négatives, y compris zéro, sinon on obtient des résultats contradictoires dans l'interprétation économique des coefficients, ce qui ne peut pas être le cas. Ainsi, le coefficient est significatif si l'intervalle de confiance obtenu ne couvre pas zéro.
Exemple 7.4. D'après l'exemple 7.1 :
a) Construire un modèle de régression linéaire appariée de la dépendance du bénéfice des ventes sur le prix de vente à l'aide d'un logiciel de traitement de données.
b) Évaluez la signification de l'équation de régression dans son ensemble, en utilisant F- Critère de Fisher à a=0,05.
c) Évaluer la signification des coefficients du modèle de régression en utilisant t-Critère d'étudiant pour α=0,05 et α=0,1.
Pour l'analyse de régression, nous utilisons le bureau standard Programme EXCEL. Nous allons construire un modèle de régression à l'aide de l'outil REGRESSION des paramètres ANALYSIS PACKAGE (Fig. 7.5), qui se lance comme suit :
ServiceAnalyse des donnéesRÉGRESSIONOK.

Fig.7.5. Utilisation de l'outil RÉGRESSION
Dans la boîte de dialogue RÉGRESSION, dans le champ Intervalle d'entrée Y, entrez l'adresse de la plage de cellules contenant la variable dépendante. Dans le champ Intervalle de saisie X, saisissez les adresses d'une ou plusieurs plages contenant les valeurs des variables indépendantes. La case Libellés sur la première ligne est activée si les en-têtes de colonne sont également sélectionnés. Sur la fig. 7.6. montré formulaire d'écran calcul d'un modèle de régression à l'aide de l'outil REGRESSION.

Riz. 7.6. Construire un modèle de régression appariée en utilisant
Outil RÉGRESSION
À la suite du travail de l'outil REGRESSION, le protocole d'analyse de régression suivant est formé (Fig. 7.7).

Riz. 7.7. Protocole d'analyse de régression
L'équation de la dépendance du bénéfice des ventes au prix de vente a la forme :
Nous allons estimer la signification de l'équation de régression en utilisant F- Critère de Fisher. Sens F- Le critère de Fisher est issu du tableau "Avariance analysis" du protocole EXCEL (Fig. 7.7.). Valeur estimée F- critère 53 372. Valeur du tableau F- critère au seuil de signification α=0,05 et le nombre de degrés de liberté ![]() est 4.964. Car
est 4.964. Car ![]() , alors l'équation est considérée comme significative.
, alors l'équation est considérée comme significative.
Valeurs estimées t-Les critères de Student pour les coefficients de l'équation de régression sont donnés dans le tableau résultant (Fig. 7.7). Valeur du tableau t-Test de Student au niveau de signification α=0,05 et 10 degrés de liberté est 2,228. Pour le coefficient de régression un, d'où le coefficient un insignifiant. Pour le coefficient de régression b, donc le coefficient b important.
Nous allons vérifier la significativité de l'équation de régression basée sur
Test F de Fisher :
La valeur du test F de Fisher se trouve dans le tableau Analyse de variance du protocole Excel. La valeur tabulaire du critère F avec une probabilité de confiance α = 0,95 et le nombre de degrés de liberté égal à v1 = k = 2 et v2 = n – k – 1= 50 – 2 – 1 = 47 est 0,051.
Puisque Fcalc > Ftabl, l'équation de régression doit être reconnue comme significative, c'est-à-dire qu'elle peut être utilisée pour l'analyse et la prévision.
L'évaluation de la significativité des coefficients du modèle obtenu, à partir des résultats du rapport Excel, peut se faire de trois manières.
Le coefficient de l'équation de régression est reconnu comme significatif si :
1) la valeur observée de la statistique t de Student pour ce coefficient est supérieure à la valeur critique (tableau) de la statistique de Student (pour un niveau de signification donné, par exemple, α = 0,05, et le nombre de degrés de liberté df = n – k – 1, où n est le nombre d'observations et k est le nombre de facteurs dans le modèle) ;
2) La valeur p de la statistique t de Student pour ce coefficient est inférieure au seuil de signification, par exemple, α = 0,05 ;
3) l'intervalle de confiance pour ce coefficient, calculé avec une certaine probabilité de confiance (par exemple, 95%), ne contient pas de zéro à l'intérieur de lui-même, c'est-à-dire que les limites inférieure à 95% et supérieure à 95% de l'intervalle de confiance ont les mêmes signes .
Signification des coefficients un1 et un2 Vérifions les deuxième et troisième méthodes :
valeur p ( un1 ) = 0,00 < 0,01 < 0,05.
valeur p ( un2 ) = 0,00 < 0,01 < 0,05.
Par conséquent, les coefficients un1 et un2 sont significatifs au seuil de 1 %, et encore plus au seuil de signification de 5 %. Les limites inférieure et supérieure à 95 % de l'intervalle de confiance ont les mêmes signes, par conséquent, les coefficients un1 et un2 important.
Définition d'une variable explicative à partir de laquelle
La variance des perturbations aléatoires peut en dépendre.
Vérification du respect de la condition d'homoscédasticité
Résidus selon le test de Goldfeld-Quandt
Lors du test de la prémisse MCO d'homoscédasticité des résidus dans un modèle de régression multiple, il faut d'abord déterminer par rapport auquel des facteurs la variance des résidus est la plus violée. Cela peut être fait en examinant visuellement les parcelles résiduelles pour chacun des facteurs inclus dans le modèle. Celle des variables explicatives, dont dépend davantage la variance des perturbations aléatoires, sera ordonnée par valeurs réelles croissantes lors de la vérification du test de Goldfeld-Quandt. Les graphiques sont faciles à obtenir dans le rapport, qui est généré à la suite de l'utilisation de l'outil de régression dans le package d'analyse de données).


Graphiques des résidus pour chacun des facteurs du modèle à deux facteurs
D'après les graphiques présentés, on peut voir que la variance des soldes est la plus violée par rapport au facteur Créances à court terme.
Vérifions la présence d'homoscédasticité dans les résidus du modèle à deux facteurs basé sur le test de Goldfeld-Quandt.
Trions les variables Y et X2 par ordre croissant du facteur X4 (dans Excel, vous pouvez utiliser la commande Données - Trier par ordre croissant X4) :
|
Données triées par ordre croissant X4 : |
||
|
Somme |
111234876536,511 |
||||
|
966570797682,068 |
|||||
|
455748832843,413 |
|||||
|
232578961097,877 |
|||||
|
834043911651,192 |
|||||
|
193722998259,505 |
|||||
|
1246409153509,290 |
|||||
|
31419681912489,100 |
|||||
|
2172804245053,280 |
|||||
|
768665257272,099 |
|||||
|
2732445494273,330 |
|||||
|
163253156450,331 |
|||||
|
18379855056009,900 |
|||||
|
10336693841766,000 |
|||||
|
Somme |
69977593738424,600 |
Définir des équations
Y = -27275.746 + 0.126X2 + 1.817X4
Y = 61439.511 + 0.228X2 + 0.140X4
Les résultats de ce tableau ont été obtenus à l'aide de l'outil de régression tour à tour pour chacune des populations obtenues.
4. Trouver le rapport des sommes résiduelles résultantes des carrés
(le numérateur doit être un montant supérieur):
5. La conclusion sur la présence d'homoscédasticité des résidus est faite à l'aide du test F de Fisher avec un niveau de signification α = 0,05 et deux degrés de liberté identiques k1 = k2 = == 17
où p est le nombre de paramètres de l'équation de régression :
Ftable (0,05 ; 17 ; 17) = 9,28.
Puisque Ftabl > R, l'homoscédasticité est confirmée dans les résidus de la régression à deux facteurs.