Le critère φ* est la transformation angulaire de Fisher. Fonction Fisher dans Excel et exemples de son travail
Critère de Fisher
Le critère de Fisher est utilisé pour tester l'hypothèse sur l'égalité des variances de deux populations générales distribuées selon la loi normale. C'est un critère paramétrique.
Le test F de Fisher est appelé le rapport de variance, car il est formé comme le rapport de deux estimations non biaisées comparées des variances.
Soit deux échantillons obtenus à la suite d'observations. Sur cette base, les écarts et  ayant
ayant  et
et  degrés de liberté. On supposera que le premier échantillon est tiré de la population générale avec une variance
degrés de liberté. On supposera que le premier échantillon est tiré de la population générale avec une variance  , et le second - de la population générale avec une variance
, et le second - de la population générale avec une variance  . L'hypothèse nulle est émise sur l'égalité des deux variances, c'est-à-dire H0 :
. L'hypothèse nulle est émise sur l'égalité des deux variances, c'est-à-dire H0 :  ou . Pour rejeter cette hypothèse, il est nécessaire de prouver la significativité de la différence à un niveau de significativité donné.
ou . Pour rejeter cette hypothèse, il est nécessaire de prouver la significativité de la différence à un niveau de significativité donné.  .
.
La valeur du critère est calculée par la formule :
Évidemment, si les variances sont égales, la valeur du critère sera égale à un. Dans d'autres cas, il sera supérieur (inférieur) à un.
Le critère a une distribution de Fisher  . Le test de Fisher est un test bilatéral et l'hypothèse nulle
. Le test de Fisher est un test bilatéral et l'hypothèse nulle  rejeté en faveur de l'alternative
rejeté en faveur de l'alternative  si . Ici où
si . Ici où  sont les volumes des premier et deuxième échantillons, respectivement.
sont les volumes des premier et deuxième échantillons, respectivement.
Le système STATISTICA implémente un test unilatéral de Fisher, c'est-à-dire comme toujours prendre la dispersion maximale. Dans ce cas, l'hypothèse nulle est rejetée en faveur de l'alternative si .
Exemple
Que la tâche soit définie pour comparer l'efficacité de la formation de deux groupes d'étudiants. Le niveau de progression caractérise le niveau de gestion du processus d'apprentissage, et la dispersion caractérise la qualité de la gestion des apprentissages, le degré d'organisation du processus d'apprentissage. Les deux indicateurs sont indépendants et cas général doivent être considérés conjointement. Le niveau de progression (attente mathématique) de chaque groupe d'élèves est caractérisé par une moyenne arithmétique  et , et la qualité est caractérisée par les variances d'échantillon correspondantes des estimations : et . Lors de l'évaluation du niveau de performance actuel, il s'est avéré qu'il est le même pour les deux étudiants :
et , et la qualité est caractérisée par les variances d'échantillon correspondantes des estimations : et . Lors de l'évaluation du niveau de performance actuel, il s'est avéré qu'il est le même pour les deux étudiants :  == 4.0. Exemples d'écarts :
== 4.0. Exemples d'écarts : 
 et
et  . Le nombre de degrés de liberté correspondant à ces estimations :
. Le nombre de degrés de liberté correspondant à ces estimations :  et
et  . Ainsi, pour établir des différences dans l'efficacité de la formation, on peut utiliser la stabilité des performances scolaires, c'est-à-dire testons l'hypothèse.
. Ainsi, pour établir des différences dans l'efficacité de la formation, on peut utiliser la stabilité des performances scolaires, c'est-à-dire testons l'hypothèse.
Calculer  (le numérateur doit avoir une grande variance), . D'après les tableaux ( STATISTIQUES –
ProbabilitéDistributioncalculatrice)
nous trouvons , qui est inférieur à celui calculé, par conséquent, l'hypothèse nulle doit être rejetée en faveur de l'alternative . Cette conclusion peut ne pas satisfaire le chercheur, puisqu'il s'intéresse à la vraie valeur du rapport
(le numérateur doit avoir une grande variance), . D'après les tableaux ( STATISTIQUES –
ProbabilitéDistributioncalculatrice)
nous trouvons , qui est inférieur à celui calculé, par conséquent, l'hypothèse nulle doit être rejetée en faveur de l'alternative . Cette conclusion peut ne pas satisfaire le chercheur, puisqu'il s'intéresse à la vraie valeur du rapport  (nous avons toujours une grande variance dans le numérateur). Lors de la vérification d'un critère unilatéral, nous obtenons , qui est inférieur à la valeur calculée ci-dessus. Ainsi, l'hypothèse nulle doit être rejetée en faveur de l'alternative.
(nous avons toujours une grande variance dans le numérateur). Lors de la vérification d'un critère unilatéral, nous obtenons , qui est inférieur à la valeur calculée ci-dessus. Ainsi, l'hypothèse nulle doit être rejetée en faveur de l'alternative.
Test de Fisher dans le programme STATISTICA sous environnement Windows
Pour un exemple de test d'hypothèse (critère de Fisher), nous utilisons (créons) un fichier à deux variables (fisher.sta) :
Riz. 1. Tableau à deux variables indépendantes
Pour tester l'hypothèse, il faut dans les statistiques de base ( De baseStatistiquesetles tables) choisissez Test de Student pour les variables indépendantes. ( test t, indépendant, par variables).

Riz. 2. Tester des hypothèses paramétriques
Après avoir sélectionné les variables et appuyé sur la touche Sommaire les valeurs des écarts types et du test de Fisher sont calculées. De plus, le niveau de signification est déterminé p, où la différence est insignifiante.

Riz. 3. Résultats du test de l'hypothèse (test F)
Utilisant Probabilitécalculatrice et en définissant la valeur des paramètres, vous pouvez tracer la distribution de Fisher avec une marque de la valeur calculée.

Riz. 4. Zone d'acceptation (rejet) de l'hypothèse (critère F)
Sources.
Tester des hypothèses sur la relation de deux variances
URL : /tryphonov3/terms3/testdi.htm
Cours 6. :8080/resources/math/mop/lections/lection_6.htm
F - Critère de Fisher
URL : /home/portal/applications/Multivariataadvisor/F-Fisheer/F-Fisheer.htm
Théorie et pratique de la recherche probabiliste et statistique.
URL : /active/referats/read/doc-3663-1.html
F - Critère de Fisher
La signification de l'équation de régression multiple dans son ensemble, ainsi que dans la régression appariée, est évaluée à l'aide du critère de Fisher :
 ,
(2.22)
,
(2.22)
où  est la somme factorielle des carrés par degré de liberté ;
est la somme factorielle des carrés par degré de liberté ;  est la somme résiduelle des carrés par degré de liberté ;
est la somme résiduelle des carrés par degré de liberté ;  – coefficient (indice) de détermination multiple;
– coefficient (indice) de détermination multiple;  est le nombre de paramètres pour les variables
est le nombre de paramètres pour les variables  (dans régression linéaire coïncide avec le nombre de facteurs inclus dans le modèle);
(dans régression linéaire coïncide avec le nombre de facteurs inclus dans le modèle);  est le nombre d'observations.
est le nombre d'observations.
La signification non seulement de l'équation dans son ensemble, mais également du facteur inclus en plus dans le modèle de régression est évaluée. La nécessité d'une telle évaluation est due au fait que tous les facteurs inclus dans le modèle ne peuvent pas augmenter de manière significative la part de la variation expliquée de l'attribut résultant. De plus, s'il y a plusieurs facteurs dans le modèle, ils peuvent être introduits dans le modèle selon des séquences différentes. En raison de la corrélation entre les facteurs, la significativité d'un même facteur peut être différente selon la séquence de son introduction dans le modèle. La mesure pour évaluer l'inclusion d'un facteur dans le modèle est la  -critère, c'est-à-dire
-critère, c'est-à-dire  .
.
Privé  -critère est basé sur la comparaison de l'augmentation de la variance factorielle, due à l'influence d'un facteur supplémentaire inclus, avec la variance résiduelle par degré de liberté selon le modèle de régression dans son ensemble. À vue générale pour le facteur
-critère est basé sur la comparaison de l'augmentation de la variance factorielle, due à l'influence d'un facteur supplémentaire inclus, avec la variance résiduelle par degré de liberté selon le modèle de régression dans son ensemble. À vue générale pour le facteur  privé
privé  -critère est défini comme
-critère est défini comme
 ,
(2.23)
,
(2.23)
où  – coefficient de détermination multiple pour un modèle avec un ensemble complet de facteurs,
– coefficient de détermination multiple pour un modèle avec un ensemble complet de facteurs,  - le même indicateur, mais sans inclure le facteur dans le modèle
- le même indicateur, mais sans inclure le facteur dans le modèle  ,
, est le nombre d'observations,
est le nombre d'observations,  est le nombre de paramètres du modèle (sans terme libre).
est le nombre de paramètres du modèle (sans terme libre).
La valeur réelle du quotient  -le critère est comparé au tableau au seuil de signification
-le critère est comparé au tableau au seuil de signification  et le nombre de degrés de liberté : 1 et
et le nombre de degrés de liberté : 1 et  . Si la valeur réelle
. Si la valeur réelle  dépasse
dépasse  , alors inclusion supplémentaire facteur a
, alors inclusion supplémentaire facteur a  dans le modèle est statistiquement justifié et le coefficient de régression net
dans le modèle est statistiquement justifié et le coefficient de régression net  avec un facteur
avec un facteur  statistiquement significatif. Si la valeur réelle
statistiquement significatif. Si la valeur réelle  inférieur au tableau, puis inclusion supplémentaire dans le modèle du facteur
inférieur au tableau, puis inclusion supplémentaire dans le modèle du facteur  n'augmente pas significativement la proportion de la variation expliquée du trait
n'augmente pas significativement la proportion de la variation expliquée du trait  , par conséquent, il est inapproprié de l'inclure dans le modèle ; coefficient de régression à facteur donné dans ce cas est statistiquement non significatif.
, par conséquent, il est inapproprié de l'inclure dans le modèle ; coefficient de régression à facteur donné dans ce cas est statistiquement non significatif.
Pour une équation à deux facteurs, les quotients  -les critères ressemblent à :
-les critères ressemblent à :
 ,
, . (2.23a)
. (2.23a)
Avec l'aide d'un privé  -test, vous pouvez tester la signification de tous les coefficients de régression en supposant que chaque facteur pertinent
-test, vous pouvez tester la signification de tous les coefficients de régression en supposant que chaque facteur pertinent  entrée dans l'équation de régression multiple en dernier.
entrée dans l'équation de régression multiple en dernier.
-Test de Student pour l'équation de régression multiple.
Privé  -critère évalue la significativité des coefficients de régression pure. Connaître l'ampleur
-critère évalue la significativité des coefficients de régression pure. Connaître l'ampleur  , il est possible de déterminer
, il est possible de déterminer  -critère du coefficient de régression à
-critère du coefficient de régression à  -ème facteur,
-ème facteur,  , à savoir :
, à savoir :
 .
(2.24)
.
(2.24)
Estimation de la significativité des coefficients de régression pure par  -Le critère de l'étudiant peut être effectué sans calcul privé
-Le critère de l'étudiant peut être effectué sans calcul privé  -Critères. Dans ce cas, comme dans la régression par paires, la formule suivante est utilisée pour chaque facteur :
-Critères. Dans ce cas, comme dans la régression par paires, la formule suivante est utilisée pour chaque facteur :
 ,
(2.25)
,
(2.25)
où  est le coefficient de régression net avec le facteur
est le coefficient de régression net avec le facteur  ,
, est l'erreur quadratique moyenne (type) du coefficient de régression
est l'erreur quadratique moyenne (type) du coefficient de régression  .
.
Pour l'équation régression multiple l'erreur quadratique moyenne du coefficient de régression peut être déterminée par la formule suivante :
 ,
(2.26)
,
(2.26)
où 
 ,
, - écart type pour la caractéristique
- écart type pour la caractéristique  ,
, est le coefficient de détermination de l'équation de régression multiple,
est le coefficient de détermination de l'équation de régression multiple,  – coefficient de détermination de la dépendance du facteur
– coefficient de détermination de la dépendance du facteur  avec tous les autres facteurs de l'équation de régression multiple ;
avec tous les autres facteurs de l'équation de régression multiple ;  est le nombre de degrés de liberté pour la somme résiduelle des écarts au carré.
est le nombre de degrés de liberté pour la somme résiduelle des écarts au carré.
Comme vous pouvez le voir, pour utiliser cette formule, vous avez besoin d'une matrice de corrélation interfactorielle et du calcul des coefficients de détermination correspondants en l'utilisant  . Alors, pour l'équation
. Alors, pour l'équation  évaluation de la significativité des coefficients de régression
évaluation de la significativité des coefficients de régression  ,
, ,
, implique le calcul de trois coefficients interfactoriels de détermination :
implique le calcul de trois coefficients interfactoriels de détermination :  ,
, ,
, .
.
Interrelation des indicateurs du coefficient de corrélation partielle, privé  -critères et
-critères et  -Le test de Student pour les coefficients de régression pure peut être utilisé dans la procédure de sélection des facteurs. L'élimination des facteurs lors de la construction de l'équation de régression par la méthode d'élimination peut pratiquement être effectuée non seulement par des coefficients de corrélation partielle, en excluant à chaque étape le facteur avec la plus petite valeur non significative du coefficient de corrélation partielle, mais également par les valeurs
-Le test de Student pour les coefficients de régression pure peut être utilisé dans la procédure de sélection des facteurs. L'élimination des facteurs lors de la construction de l'équation de régression par la méthode d'élimination peut pratiquement être effectuée non seulement par des coefficients de corrélation partielle, en excluant à chaque étape le facteur avec la plus petite valeur non significative du coefficient de corrélation partielle, mais également par les valeurs  et
et  .
Privé
.
Privé  -critère est largement utilisé dans la construction du modèle par l'inclusion de variables et la méthode de régression pas à pas.
-critère est largement utilisé dans la construction du modèle par l'inclusion de variables et la méthode de régression pas à pas.
Pour comparer deux populations distribuées normalement qui n'ont pas de différences dans les moyennes d'échantillon, mais il y a une différence dans les variances, utilisez Critère de Fisher. Le critère réel est calculé par la formule :
où le numérateur est la plus grande valeur de la variance de l'échantillon et le dénominateur est la plus petite valeur. Pour déduire la signification des différences entre les échantillons, nous utilisons LE PRINCIPE DE BASE
test d'hypothèses statistiques. Points critiques pour  sont contenus dans le tableau. L'hypothèse nulle est rejetée si la valeur réelle
sont contenus dans le tableau. L'hypothèse nulle est rejetée si la valeur réelle 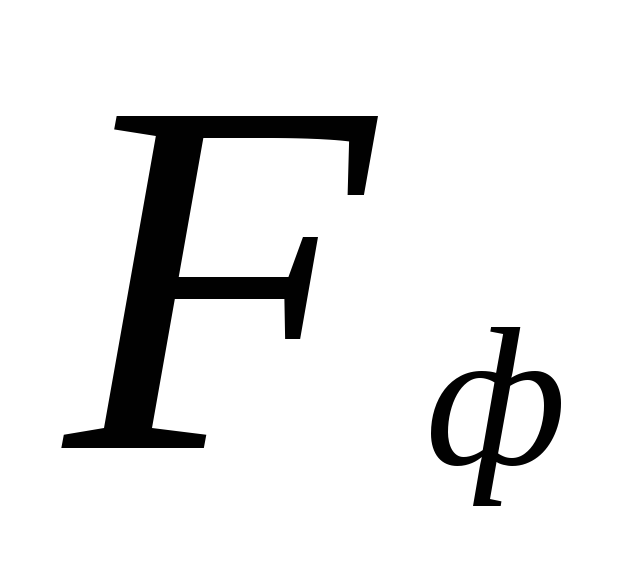 dépassera ou sera égal à la valeur critique (standard)
dépassera ou sera égal à la valeur critique (standard)  cette valeur pour le niveau de signification accepté
et nombre de degrés de liberté k
1
=
n
gros
-1
;
k
2
=
n
moindre
-1
.
cette valeur pour le niveau de signification accepté
et nombre de degrés de liberté k
1
=
n
gros
-1
;
k
2
=
n
moindre
-1
.
Exemple: lors de l'étude de l'effet d'un certain médicament sur le taux de germination des graines, il a été constaté que dans le lot expérimental de graines et de contrôle, le taux de germination moyen est le même, mais il existe une différence de dispersion.  =1250,
=1250, =417. Les tailles d'échantillon sont les mêmes et égales à 20.
=417. Les tailles d'échantillon sont les mêmes et égales à 20. 
 =2.12. L'hypothèse nulle est donc rejetée.
=2.12. L'hypothèse nulle est donc rejetée.
dépendance de corrélation. Coefficient de corrélation et ses propriétés. Équations de régression.
UNE TÂCHE l'analyse de corrélation se réduit à :
Établir la direction et la forme de communication entre les panneaux ;
mesurer son étanchéité.
fonctionnel une relation biunivoque entre les variables est appelée lorsqu'une certaine valeur d'une variable (indépendante) X , appelé l'argument, correspond à une certaine valeur d'une autre variable (dépendante) à appelé une fonction. ( Exemple: dépendance de la vitesse d'une réaction chimique à la température ; dépendance de la force d'attraction sur les masses des corps attirés et la distance entre eux).
corrélation une relation entre variables de nature statistique est appelée, lorsqu'une certaine valeur d'une caractéristique (considérée comme une variable indépendante) correspond à toute une série de valeurs numériques d'une autre caractéristique. ( Exemple: relation entre rendement et pluviométrie ; entre la taille et le poids, etc.).
Champ de corrélation est un ensemble de points dont les coordonnées sont égales aux paires de valeurs variables obtenues expérimentalement X et à .
Par la forme du champ de corrélation, on peut juger de la présence ou de l'absence d'une connexion et de son type.




La connexion s'appelle positif si l'augmentation d'une variable augmente une autre variable.
La connexion s'appelle négatif lorsqu'une augmentation d'une variable diminue une autre variable.
La connexion s'appelle linéaire
, s'il peut être représenté analytiquement comme 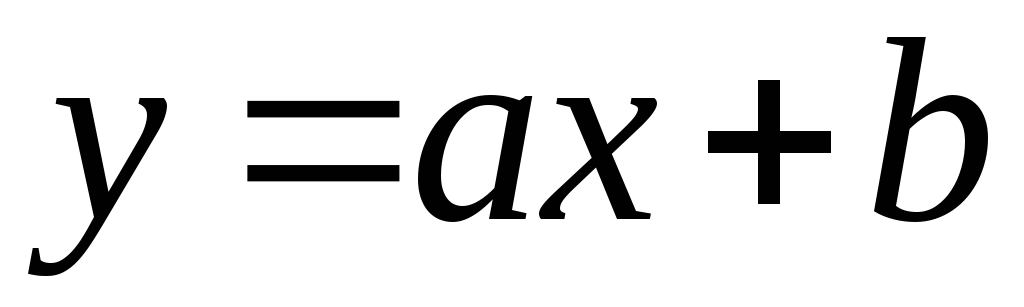 .
.
Un indicateur de l'étanchéité de la connexion est Coefficient de corrélation . Le coefficient de corrélation empirique est donné par :

Le coefficient de corrélation est compris entre -1 avant de 1 et caractérise le degré de proximité entre les grandeurs X et y . Si un:

La corrélation entre les caractéristiques peut être décrite différentes façons. En particulier, toute forme de connexion peut être exprimée par une équation générale 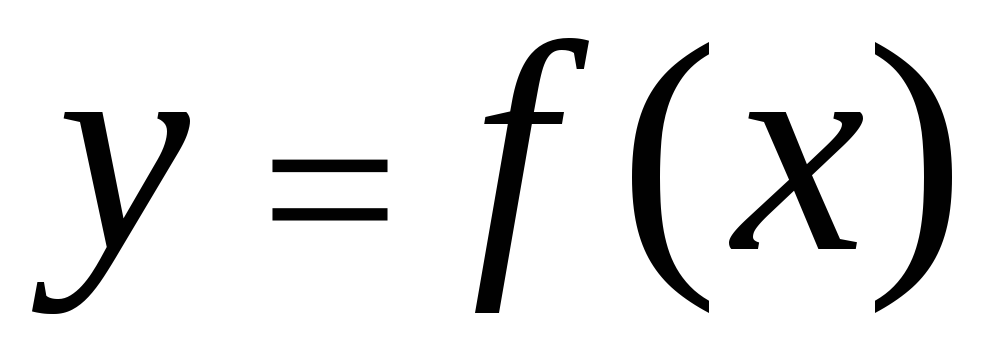 . Équation de type
. Équation de type  et
et 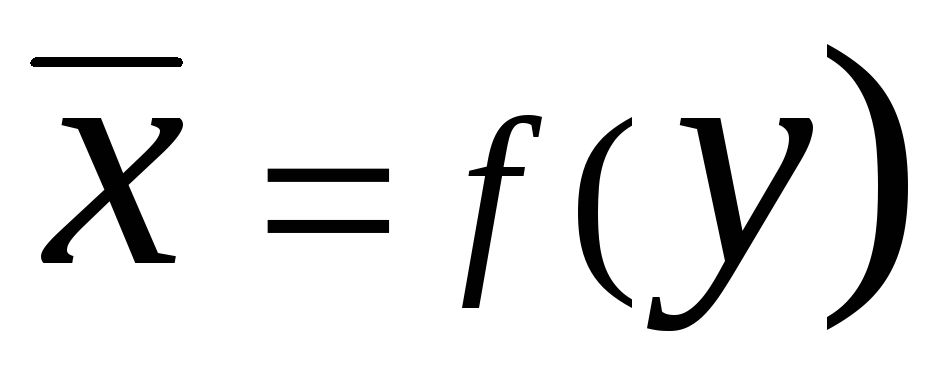 appelé régression
. Équation de régression directe à
sur le X
en général peut s'écrire sous la forme
appelé régression
. Équation de régression directe à
sur le X
en général peut s'écrire sous la forme

Équation de régression directe X sur le à ressemble généralement

Les valeurs les plus probables des coefficients un et dans, Avec et ré peut être calculé, par exemple, en utilisant la méthode des moindres carrés.
)Calcul du critère φ*
1. Déterminez les valeurs de l'attribut qui serviront de critère pour diviser les sujets en ceux qui "ont un effet" et ceux qui "n'ont aucun effet". Si le trait est quantifié, utilisez le critère λ pour trouver le point de partage optimal.
2. Dessinez un tableau à quatre cellules (synonyme : quatre champs) composé de deux colonnes et de deux lignes. La première colonne est « il y a un effet » ; la deuxième colonne est "sans effet" ; première ligne à partir du haut - 1 groupe (échantillon); la deuxième ligne - 2 groupe (échantillon).
4. Comptez le nombre de sujets du premier échantillon qui n'ont "aucun effet" et inscrivez ce nombre dans la cellule supérieure droite du tableau. Calculez la somme des deux premières cellules. Il doit correspondre au nombre de sujets du premier groupe.
6. Comptez le nombre de sujets du deuxième échantillon qui n'ont "aucun effet" et inscrivez ce nombre dans la cellule en bas à droite du tableau. Calculez la somme des deux cellules du bas. Il doit correspondre au nombre de sujets du deuxième groupe (échantillon).
7. Déterminez le pourcentage de sujets qui "ont un effet" en rapportant leur nombre à total sujets de ce groupe (échantillon). Notez les pourcentages obtenus dans les cellules en haut à gauche et en bas à gauche du tableau, respectivement, entre parenthèses afin de ne pas les confondre avec des valeurs absolues.
8. Vérifiez si l'un des pourcentages correspondants est égal à zéro. Si c'est le cas, essayez de changer cela en déplaçant le point de partage des groupes d'un côté ou de l'autre. Si cela est impossible ou indésirable, rejetez le critère φ* et utilisez le critère χ2.
9. Déterminer selon le tableau. XII Annexe 1 les valeurs des angles φ pour chacun des pourcentages comparés.
où : φ1 - l'angle correspondant au pourcentage le plus élevé ;
φ2 - angle correspondant à un pourcentage inférieur ;
N1 - nombre d'observations dans l'échantillon 1 ;
N2 - nombre d'observations dans l'échantillon 2.
11. Comparez la valeur obtenue φ* avec les valeurs critiques : φ* ≤1,64 (р<0,05) и φ* ≤2,31 (р<0,01).
Si φ*emp ≤φ*cr. H0 est rejeté.
Si nécessaire, déterminer le niveau exact de signification du φ*emp obtenu selon le tableau. XIII Annexe 1.
Cette méthode est décrite dans de nombreux manuels (Plokhinsky N.A., 1970 ; Gubler E.V., 1978 ; Ivanter E.V., Korosov A.V., 1992, etc.) Cette description est basée sur la version de la méthode qui a été développée et présentée par E.V. Gubler.
Objet du critère φ*
Le test de Fisher est conçu pour comparer deux échantillons en fonction de la fréquence d'apparition d'un effet (indicateur) intéressant le chercheur. Plus il est grand, plus les différences sont fiables.
Description du critère
Le critère évalue la fiabilité des différences entre les pourcentages de deux échantillons dans lesquels l'effet (indicateur) qui nous intéresse est enregistré. Au sens figuré, nous comparons les 2 meilleurs morceaux coupés de 2 tartes entre eux et décidons lequel est vraiment le plus gros.
L'essence de la transformation angulaire de Fisher est la conversion de pourcentages en angles centraux, qui sont mesurés en radians. Un pourcentage plus grand correspondra à un angle φ plus grand, et un pourcentage plus petit correspondra à un angle plus petit, mais les relations ici ne sont pas linéaires :
où P est un pourcentage exprimé en fractions d'unité (voir Fig. 5.1).
Avec un écart croissant entre les angles φ 1 et φ 2 et une augmentation du nombre d'échantillons, la valeur du critère augmente. Plus la valeur φ* est élevée, plus il est probable que les différences soient significatives.
Hypothèses
H 0 : Part des personnes, qui manifestent l'effet à l'étude, dans l'échantillon 1 pas plus que dans l'échantillon 2.
H 1 : La proportion de personnes qui présentent l'effet à l'étude est plus importante dans l'échantillon 1 que dans l'échantillon 2.
Représentation graphique d'un critère φ*
La méthode de transformation angulaire est un peu plus abstraite que le reste des critères.
La formule à laquelle E. V. Gubler adhère lors du calcul des valeurs de φ suppose que 100% est l'angle φ=3,142, c'est-à-dire la valeur arrondie π=3,14159... Cela nous permet de représenter les échantillons comparés sous la forme de deux demi-cercles, dont chacun symbolise 100% du nombre de leur échantillon. Les pourcentages de sujets avec "effet" seront présentés sous forme de secteurs formés par les angles centraux φ. Sur la Fig. La figure 5.2 montre deux demi-cercles illustrant l'exemple 1. Dans le premier échantillon, 60 % des sujets ont résolu le problème. Ce pourcentage correspond à l'angle φ = 1,772. Dans le second échantillon, 40% des sujets ont résolu le problème. Ce pourcentage correspond à l'angle φ =1,369.
Le critère φ* permet de déterminer si l'un des angles est statistiquement significativement supérieur à l'autre pour des tailles d'échantillons données.
Restrictions des critères φ*
1. Aucune des parts comparées ne doit être égale à zéro. Formellement, il n'y a aucun obstacle à l'application de la méthode φ dans les cas où la proportion d'observations dans l'un des échantillons est de 0. Cependant, dans ces cas, le résultat peut être déraisonnablement élevé (Gubler E.V., 1978, p. 86) .
2. Haut il n'y a pas de limite dans le critère φ - les échantillons peuvent être arbitrairement grands.
Plus bas la limite est de 2 observations dans l'un des échantillons. Cependant, les ratios suivants dans la taille des deux échantillons doivent être respectés :
a) s'il n'y a que 2 observations dans un échantillon, alors le second doit en avoir au moins 30 :
b) si l'un des échantillons n'a que 3 observations, alors le second doit en avoir au moins 7 :
c) si l'un des échantillons n'a que 4 observations, alors le second devrait en avoir au moins 5 :
d) àn 1 , n 2 ≥ 5 toute comparaison est possible.
En principe, il est également possible de comparer des échantillons qui ne satisfont pas à cette condition, par exemple, avec la relationn 1 =2, n 2 = 15, mais dans ces cas, il ne sera pas possible de détecter des différences significatives.
Le critère φ* n'a pas d'autres restrictions.
Prenons quelques exemples pour illustrer les possibilitéscritère φ*.
Exemple 1 : comparaison d'échantillons selon une caractéristique déterminée qualitativement.
Exemple 2 : comparaison d'échantillons selon un attribut mesuré quantitativement.
Exemple 3 : comparaison d'échantillons à la fois en termes de niveau et de distribution d'une caractéristique.
Exemple 4 : utilisation du critère φ* en combinaison avec le critèreX Kolmogorov-Smirnov afin d'obtenir le résultat le plus précis.
Exemple 1 - comparaison d'échantillons selon une caractéristique déterminée qualitativement
Dans cette utilisation du test, nous comparons le pourcentage de sujets d'un échantillon qui se caractérisent par une certaine qualité avec le pourcentage de sujets d'un autre échantillon qui se caractérisent par la même qualité.
Supposons que nous cherchions à savoir si deux groupes d'étudiants diffèrent dans leur réussite à résoudre un nouveau problème expérimental. Dans le premier groupe de 20 personnes, 12 personnes y ont fait face, et dans le deuxième échantillon de 25 personnes - 10. Dans le premier cas, le pourcentage de ceux qui ont résolu le problème sera de 12/20 100% = 60%, et dans le deuxième 10/25 100% = 40%. Ces pourcentages diffèrent-ils significativement avec les donnéesn 1 etn 2 ?
Il semblerait que "à vue d'oeil" on puisse déterminer que 60% est bien supérieur à 40%. Cependant, ces différences sont en réalitén 1 , n 2 non fiable.
Regardons ça. Puisque nous nous intéressons au fait de résoudre le problème, nous considérerons le succès dans la résolution du problème expérimental comme un « effet », et l'échec dans sa résolution comme l'absence d'effet.
Formulons des hypothèses.
H 0 : Part des personnesfait face à la tâche, dans le premier groupe pas plus que dans le deuxième groupe.
H 1 : La proportion de personnes ayant fait face à la tâche dans le premier groupe est plus importante que dans le second groupe.
Construisons maintenant la table dite à quatre cellules ou à quatre champs, qui est en fait une table de fréquences empiriques pour deux valeurs d'attribut : "il y a un effet" - "il n'y a pas d'effet".
Tableau 5.1
Un tableau à quatre cellules pour calculer le critère lors de la comparaison de deux groupes de sujets par le pourcentage de ceux qui ont résolu le problème.
Groupes | "Il y a un effet": la tâche est résolue | "Aucun effet": problème non résolu | Sommes |
||||
Quantité sujets de test | % partager | Quantité sujets de test | % partager | ||||
1 groupe | (60%) | (40%) | |||||
2 groupe | (40%) | (60%) | |||||
Sommes | |||||||
Dans un tableau à quatre cellules, en règle générale, les colonnes "Il y a un effet" et "Aucun effet" sont marquées en haut, et les lignes "Groupe 1" et "Groupe 2" sont à gauche. En fait, seuls les champs (cellules) A et B participent aux comparaisons, c'est-à-dire aux pourcentages de la colonne "Il y a un effet".
Selon le tableau.XIIL'annexe 1 définit les valeurs de φ correspondant aux pourcentages dans chacun des groupes.
Calculons maintenant la valeur empirique de φ* en utilisant la formule :
où φ 1 - l'angle correspondant à la plus grande part en % ;
φ 2 - l'angle correspondant à la plus petite part en % ;
n 1 - nombre d'observations dans l'échantillon 1 ;
n 2 - le nombre d'observations dans l'échantillon 2.
Dans ce cas:
Selon le tableau.XIIIL'annexe 1 détermine à quel niveau de signification correspond φ* emp=1,34:
p=0,09
Il est également possible d'établir des valeurs critiques de φ* correspondant aux niveaux de signification statistique acceptés en psychologie :
Construisons un "axe de signification".
La valeur empirique φ* obtenue est dans la zone de non-significativité.
Réponse: H 0 accepté. La proportion de personnes qui ont terminé la tâchedansle premier groupe pas plus que le deuxième groupe.
On ne peut que sympathiser avec un chercheur qui considère des différences significatives de 20% et même de 10% sans vérifier leur fiabilité par le critère φ*. Dans ce cas, par exemple, seules des différences d'au moins 24,3 % seraient significatives.
Il semble que lorsqu'on compare deux échantillons selon un critère qualitatif, le critère φ peut nous déranger plutôt que nous plaire. Ce qui semblait significatif, d'un point de vue statistique, ne l'est peut-être pas.
Beaucoup plus d'opportunités de plaire au chercheur apparaissent avec le critère de Fisher lorsque l'on compare deux échantillons selon des traits mesurés quantitativement et que l'on peut faire varier "l'effet".
Exemple 2 - comparaison de deux échantillons selon un attribut mesuré quantitativement
Dans cette variante d'utilisation du critère, nous comparons le pourcentage de sujets d'un échantillon qui atteignent un certain niveau d'une valeur de caractéristique avec le pourcentage de sujets qui atteignent ce niveau dans un autre échantillon.
Dans une étude de G. A. Tlegenova (1990), sur 70 jeunes hommes scolarisés dans des écoles professionnelles âgés de 14 à 16 ans, 10 sujets avec un score élevé sur l'échelle d'agressivité et 11 sujets avec un score faible sur l'échelle d'agressivité ont été sélectionnés sur la base de résultats d'une enquête utilisant le Freiburg Personality Questionnaire. Il s'agit de déterminer si les groupes de jeunes hommes agressifs et non agressifs diffèrent quant à la distance qu'ils choisissent spontanément dans une conversation avec un condisciple. Les données de G. A. Tlegenova sont présentées dans le tableau. 5.2. On constate que les jeunes hommes agressifs choisissent plus souvent une distance de 50cm ou même moins, tandis que les jeunes non agressifs sont plus susceptibles de choisir des distances supérieures à 50 cm.
Or on peut considérer une distance de 50 cm comme critique et considérer que si la distance choisie par le sujet testé est inférieure ou égale à 50 cm, alors il y a un « effet », et si la distance choisie est supérieure à 50 cm, alors il n'y a pas d'effet. On voit que dans le groupe des jeunes hommes agressifs, l'effet est observé chez 7 sur 10, soit dans 70% des cas, et dans le groupe des jeunes hommes non agressifs, chez 2 sur 11, soit dans 18,2 % des cas. Ces pourcentages peuvent être comparés à l'aide de la méthode φ* pour établir la validité des différences entre eux.
Tableau 5.2
Indicateurs de distance (en cm) choisis par les jeunes hommes agressifs et non agressifs lors d'une conversation avec un camarade de classe (d'après G.A. Tlegenova, 1990)
Groupe 1 : garçons avec des scores élevés sur l'échelle d'agressivitéFPI- R (n 1 =10) | Groupe 2 : garçons avec de faibles scores sur l'échelle d'agressivitéFPI- R (n 2 =11) |
|||
d(c m ) | % partager | d(c M ) | % partager |
|
"Il y a Effet" ré≤50cm | ||||
18,2% |
||||
"Pas effet" j>50 cm | ||||
80 AQ | 81,8% |
|||
Sommes | 100% | 100% |
||
Moyen | 5b :o | 77.3 | ||
Formulons des hypothèses.
H 0 ré ≤ 50 voyez, il n'y a pas plus de garçons agressifs dans le groupe que dans le groupe de garçons non agressifs.
H 1 : Proportion de personnes qui choisissent une distanceré≤ 50 cm, dans le groupe des garçons agressifs plus que dans le groupe des garçons non agressifs. Construisons maintenant la table dite à quatre cellules.
Tableau 53
Un tableau à quatre cellules pour le calcul du critère φ* lors de la comparaison de groupes d'agressifs (nf=10) et garçons non agressifs (n2=11)
Groupes | "Il y a un effet": ré≤50 | "Aucun effet." ré>50 | Sommes |
||||
Nombre de sujets de test | (% partager) | Nombre de sujets de test | (% partager) | ||||
Groupe 1 - garçons agressifs | (70%) | (30%) | |||||
Groupe 2 - garçons non agressifs | (180%) | (81,8%) | |||||
Somme | |||||||
Selon le tableau.XIIL'annexe 1 définit les valeurs de φ correspondant au pourcentage de "l'effet" dans chacun des groupes.
La valeur empirique φ* obtenue est dans la zone de signification.
Réponse: H 0 rejeté. acceptéH 1 . La proportion de personnes qui choisissent une distance dans une conversation inférieure ou égale à 50 cm est plus importante dans le groupe des garçons agressifs que dans le groupe des garçons non agressifs
D'après le résultat obtenu, on peut conclure que les garçons plus agressifs choisissent plus souvent une distance de moins d'un demi-mètre, tandis que les garçons non agressifs choisissent plus souvent une distance de plus d'un demi-mètre. On voit que les jeunes hommes agressifs communiquent en réalité à la frontière des zones intime (0-46 cm) et personnelle (à partir de 46 cm). Nous rappelons cependant que la distance intime entre partenaires est l'apanage non seulement des bonnes relations proches, maisetcombat au corps à corps (SalleE. J., 1959).
Exemple 3 - comparaison d'échantillons à la fois en termes de niveau et de distribution d'une caractéristique.
Dans cette variante d'utilisation du test, nous pouvons d'abord vérifier si les groupes diffèrent au niveau de n'importe quel trait, puis comparer les distributions du trait dans deux échantillons. Une telle tâche peut être pertinente dans l'analyse des différences dans les fourchettes ou la forme de distribution des estimations obtenues par les sujets à l'aide d'une nouvelle méthode.
Dans l'étude de R. T. Chirkina (1995), un questionnaire a été utilisé pour la première fois, visant à identifier une tendance à évincer les faits, les noms, les intentions et les méthodes d'action de la mémoire, en raison de complexes personnels, familiaux et professionnels. Le questionnaire a été créé avec la participation de E. V. Sidorenko sur la base des matériaux du livre 3. Freud "Psychopathologie de la vie quotidienne". Un échantillon de 50 étudiants de l'Institut pédagogique, célibataires, sans enfants, âgés de 17 à 20 ans, a été examiné à l'aide de ce questionnaire, ainsi que de la technique Menester-Corzini pour identifier l'intensité du sentiment d'insuffisance propre,ou"complexe d'infériorité"Manastèreg. J., CorsiniR. J., 1982).
Les résultats de l'enquête sont présentés dans le tableau. 5.4.
Peut-on soutenir qu'il existe des relations significatives entre l'indicateur de l'énergie de déplacement, diagnostiqué à l'aide du questionnaire, et les indicateurs d'intensité, le sentiment de sa propre insuffisance ?
Tableau 5.4
Indicateurs de l'intensité du sentiment d'insuffisance propre dans des groupes d'élèves ayant un niveau élevé (New Jersey=18) et faible (n2=24) énergie de déplacement
Groupe 1 : énergie de déplacement de 19 à 31 points (n 1 =181 | Groupe 2 : énergie de déplacement de 7 à 13 points (n 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
Sommes Moyen | 26,11 | 15,42 |
Malgré le fait que la valeur moyenne dans le groupe avec un déplacement plus vigoureux est plus élevée, 5 valeurs nulles y sont également observées. Si l'on compare les histogrammes de la distribution des estimations dans deux échantillons, on trouve alors un contraste saisissant entre eux (Fig. 5.3).
Pour comparer deux distributions, on pourrait appliquer le critèreχ 2 ou critèreλ , mais pour cela il faudrait agrandir les chiffres, et en plus, dans les deux échantillonsn <30.
Le critère φ* va nous permettre de vérifier l'effet de l'écart entre les deux distributions observées sur le graphique, si l'on accepte de considérer qu'il y a un "effet" si l'indicateur du sentiment d'insuffisance prend soit très faible (0) ou, à l'inverse, des valeurs très élevées (S30) et qu'il n'y a "aucun effet" si le score de manque est dans la moyenne, entre 5 et 25.
Formulons des hypothèses.
H 0 : Les valeurs extrêmes de l'indice d'insuffisance (soit 0, soit 30 ou plus) dans le groupe avec un refoulement plus vigoureux ne sont pas plus fréquentes que dans le groupe avec un refoulement moins vigoureux.
H 1 : Les valeurs extrêmes de l'indice d'insuffisance (soit 0, soit 30 ou plus) dans le groupe avec une répression plus vigoureuse sont plus fréquentes que dans le groupe avec une répression moins vigoureuse.
Créons un tableau à quatre cellules, pratique pour un calcul ultérieur du critère φ*.
Tableau 5.5
Tableau à quatre cellules pour le calcul du critère φ* lors de la comparaison de groupes avec une énergie de déplacement supérieure et inférieure en fonction du rapport des indicateurs d'insuffisance
Groupes | « Est efficace » : le score de déficience est de 0 ou > 30 | « Aucun effet » : score de carence de 5 à 25 | Sommes |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
Sommes | |||||
Selon le tableau.XIIEn annexe 1, nous définissons les valeurs de φ correspondant aux pourcentages comparés :
Calculons la valeur empirique de φ* :
Valeurs critiques de φ* pour toutn 1 , n 2 , comme nous nous en souvenons de l'exemple précédent, sont :
Languette.XIIIL'annexe 1 permet de déterminer plus précisément le niveau de significativité du résultat obtenu : p<0,001.
Réponse: H 0 rejeté. acceptéH 1 . Les valeurs extrêmes de l'indice d'insuffisance (soit 0, soit 30 ou plus) dans le groupe avec une énergie de déplacement plus élevée sont plus fréquentes que dans le groupe avec une énergie de déplacement plus faible.
Ainsi, les sujets avec une énergie de répression plus élevée peuvent avoir à la fois des indicateurs très élevés (30 ou plus) et très faibles (zéro) de sentiment de leur propre insuffisance. On peut supposer qu'ils refoulent à la fois leur insatisfaction et le besoin de réussir dans la vie. Ces hypothèses doivent être vérifiées plus avant.
Le résultat obtenu, quelle que soit son interprétation, confirme la possibilité du critère φ* dans l'appréciation des différences de forme de la distribution des traits dans deux échantillons.
Il y avait 50 personnes dans l'échantillon initial, mais 8 d'entre elles ont été exclues de la prise en compte car ayant un score moyen sur l'indicateur d'anergie de déplacement (14-15). Les indicateurs de l'intensité du sentiment d'insuffisance sont également moyens : 6 valeurs de 20 points et 2 valeurs de 25 points.
Les puissantes possibilités du critère φ* peuvent être vues en confirmant une hypothèse complètement différente lors de l'analyse des matériaux de cet exemple. On peut prouver, par exemple, que dans un groupe avec une énergie de répression plus élevée, l'indicateur de carence est encore plus élevé, malgré le caractère paradoxal de sa répartition dans ce groupe.
Formulons de nouvelles hypothèses.
H 0 Les valeurs les plus élevées de l'indice d'insuffisance (30 ou plus) dans le groupe avec une énergie de déplacement plus élevée ne se retrouvent pas plus souvent que dans le groupe avec une énergie de déplacement plus faible.
H 1 : Les valeurs les plus élevées de l'indice d'insuffisance (30 ou plus) dans le groupe avec une énergie de déplacement plus élevée sont plus fréquentes que dans le groupe avec une énergie de déplacement plus faible. Construisons une table à quatre champs en utilisant les données de Table. 5.4.
Tableau 5.6
Tableau à quatre cellules pour le calcul du critère φ* lors de la comparaison de groupes avec une énergie de déplacement supérieure et inférieure en fonction du niveau de l'indice de déficience
Groupes | "Il y a un effet"* l'indicateur de carence est supérieur ou égal à 30 | "Aucun effet" : le score de déficience est inférieur 30 | Sommes |
||
Groupe 1 - avec une énergie de déplacement plus élevée | (61,1%) | (38.9%) | |||
Groupe 2 - avec une énergie de déplacement inférieure | (25.0%) | (75.0%) | |||
Sommes | |||||
Selon le tableau.XIIIL'annexe 1 détermine que ce résultat correspond à un seuil de signification de p=0,008.
Réponse: Mais il est rejeté. acceptéhj: Les taux d'échec les plus élevés (30 points ou plus) du groupeAvecavec une énergie de déplacement plus élevée sont plus fréquents que dans le groupe avec une énergie de déplacement plus faible (p = 0,008).
Ainsi, nous avons pu prouver quedansgroupeAvecle déplacement plus vigoureux est dominé par les valeurs extrêmes de l'indicateur d'insuffisance, et le fait que cet indicateur est supérieur à ses valeursatteintdans ce groupe particulier.
Maintenant, nous pourrions essayer de prouver que dans le groupe avec une énergie de déplacement plus élevée, les valeurs inférieures de l'indice d'insuffisance sont également plus courantes, malgré le fait que la valeur moyennedans ce groupe plus (26,11 contre 15,42 dans le groupeAvec moins de déplacement).
Formulons des hypothèses.
H 0 : Scores de malnutrition les plus bas (néant) du groupeAvec une plus grande énergie de déplacement ne se trouve pas plus souvent que dans le groupeAvec moins d'énergie de déplacement.
H 1 : Les taux de malnutrition les plus bas (néant) se produisentdans groupe avec une énergie de déplacement plus élevée plus souvent que dans le groupeAvec déplacement moins énergique. Regroupons les données dans un nouveau tableau à quatre cellules.
Tableau 5.7
Un tableau à quatre cellules pour comparer des groupes avec différentes énergies de déplacement en termes de fréquence des valeurs nulles de l'indice de déficience
Groupes | « Il y a un effet » : l'indicateur d'insuffisance est 0 | Échec "Aucun effet" | l'exposant n'est pas 0 | Sommes |
|
Groupe 1 - avec une énergie de déplacement plus élevée | (27,8%) | (72,2%) | |||
1 groupe - avec une énergie de déplacement inférieure | (8,3%) | (91,7%) | |||
Sommes | |||||
Nous déterminons les valeurs de φ et calculons la valeur de φ* :
Réponse: H 0 rejeté. Les scores de déficience les plus bas (nil) dans le groupe avec une énergie de déplacement plus élevée sont plus fréquents que dans le groupe avec une énergie de déplacement plus faible (p<0,05).
En somme, les résultats obtenus peuvent être considérés comme la preuve d'une coïncidence partielle des concepts de complexe de Z. Freud et A. Adler.
Il est significatif qu'entre l'indicateur de l'énergie de déplacement et l'indicateur de l'intensité du sentiment de sa propre insuffisance, dans l'ensemble de l'échantillon, une corrélation linéaire positive a été obtenue (p = +0,491, p<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
Exemple 4 - utilisation du critère φ* en combinaison avec le critère λ Kolmogorov-Smirnov afin d'atteindre le maximum exactrésultat
Si des échantillons sont comparés selon certains indicateurs mesurés quantitativement, le problème se pose d'identifier le point de distribution qui peut être utilisé comme point critique pour diviser tous les sujets en ceux qui "ont un effet" et ceux qui "n'ont pas d'effet".
En principe, le point auquel on diviserait le groupe en sous-groupes, où il y a un effet et il n'y a pas d'effet, peut être choisi assez arbitrairement. Nous pouvons être intéressés par n'importe quel effet, et donc nous pouvons diviser les deux échantillons en deux parties à tout moment, tant que cela a du sens.
Cependant, afin de maximiser la puissance du test φ*, il est nécessaire de choisir le point auquel les différences entre les deux groupes comparés sont les plus importantes. Plus précisément, nous pouvons le faire en utilisant l'algorithme de calcul de critèreλ , ce qui permet de trouver le point d'écart maximal entre les deux échantillons.
Possibilité de combiner les critères φ* etλ décrit par E.V. Gubler (1978, p. 85-88). Essayons d'utiliser cette méthode pour résoudre le problème suivant.
Dans une étude conjointe de M.A. Kurochkina, E.V. Sidorenko et Yu.A. Churakova (1992) au Royaume-Uni, les médecins généralistes anglais ont été interrogés en deux catégories : a) les médecins qui ont soutenu la réforme médicale et avaient déjà transformé leurs cabinets en organisations de financement avec leur propre budget ; b) les médecins, dont les réceptions ne disposent toujours pas de fonds propres et sont entièrement financées par le budget de l'Etat. Des questionnaires ont été envoyés à un échantillon de 200 médecins, représentatif de la population générale des médecins anglais en termes de représentation des personnes de sexe, d'âge, d'ancienneté et de lieu de travail différents - dans les grandes villes ou en province.
Les réponses au questionnaire ont été envoyées par 78 médecins dont 50 travaillant dans des accueils avec fonds et 28 dans des accueils sans fonds. Chacun des médecins devait prédire quelle serait la part des réceptions avec des fonds l'année suivante, 1993. Seuls 70 médecins sur 78 qui ont envoyé des réponses ont répondu à cette question. La répartition de leurs prévisions est présentée dans le tableau. 5.8 séparément pour un groupe de médecins avec fonds et un groupe de médecins sans fonds.
Les prédictions des médecins avec des fonds et des médecins sans fonds sont-elles en quelque sorte différentes ?
Tableau 5.8
Répartition des prédictions des médecins généralistes sur la part des admissions avec fonds en 1993
Part projetée | |||
salles de réception avec fonds | médecins avec fonds (n 1 =45) | médecins sans fonds (n 2 =25) | Sommes |
1. 0 à 20% | 4 | 5 | 9 |
2. 21 à 40% | 15 | Et | 26 |
3. 41 à 60 % | 18 | 5 | 23 |
4. 61 à 80% | 7 | 4 | Et |
5. 81 à 100 % | 1 | 0 | 1 |
Sommes | 45 | 25 | 70 |
Déterminons le point d'écart maximal entre les deux distributions de réponses selon l'algorithme 15 du paragraphe 4.3 (voir tableau 5.9).
Tableau 5.9
Calcul de la différence maximale des fréquences cumulées dans les distributions des prévisions des médecins de deux groupes
Proportion projetée de familles d'accueil disposant de fonds (%) | Fréquences empiriques pour choisir une catégorie de réponse donnée | Fréquences empiriques | Fréquences empiriques cumulées | Différence (ré) |
|||
médecins avec fondation(n 1 =45) | médecins sans fonds (n 2 =25) | F* euh 1 | F* a2 | ∑F* e1 | ∑F* a1 |
||
1. 0 à 20% 2. 21 à 40% 3. 41 à 60 % 4. 61 à 80% 5. 81 à 100 % | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
La différence maximale trouvée entre les deux fréquences empiriques cumulées est0,218.
Cette différence est cumulée dans la deuxième catégorie de la prévision. Essayons d'utiliser la borne supérieure de cette catégorie comme critère pour diviser les deux échantillons en un sous-groupe où il y a un effet et un sous-groupe où il n'y a pas d'effet. On supposera qu'il y a un « effet » si ce médecin prédit de 41 à 100 % de chambres d'accueil avec des fonds en1993 année, et qu'il n'y a "aucun effet" si un médecin donné prédit 0 à 40% de chirurgies avec des fonds en1993 an. Nous combinons les catégories de prévisions 1 et 2 d'une part, et les catégories de prévisions 3, 4 et 5 d'autre part. La distribution des prévisions qui en résulte est présentée dans le tableau. 5.10.
Tableau 5.10
Répartition des prévisions pour les médecins avec fonds et les médecins sans fonds
Proportion projetée de foyers d'accueil disposant de fonds (%1 | Fréquences empiriques pour choisir une catégorie de prévision donnée | Sommes |
|
médecins avec fondation(n 1 =45) | médecins sans fonds(n 2 =25) |
||
1. de 0 à 40% | 19 | 16 | 35 |
2. de 41 à 100% | 26 | 9 | 35 |
Sommes | 45 | 25 | 70 |
Nous pouvons utiliser le tableau résultant (tableau 5.10) en testant différentes hypothèses en comparant deux de ses cellules. Nous nous souvenons qu'il s'agit de la table dite à quatre cellules ou à quatre champs.
Dans ce cas, nous cherchons à savoir si les médecins qui ont déjà des fonds prédisent réellement un mouvement plus important à l'avenir que les médecins qui n'ont pas de fonds. Par conséquent, nous croyons conditionnellement qu'il y a un « effet » lorsque la prévision tombe dans la catégorie de 41 à 100 %. Pour simplifier les calculs, nous devons maintenant faire pivoter la table de 90°, en la faisant tourner dans le sens des aiguilles d'une montre. Vous pouvez même le faire littéralement en tournant le livre avec la table. Nous pouvons maintenant passer à la feuille de travail pour calculer le critère φ* - transformation angulaire de Fisher.
Table 5.11
Tableau à quatre cellules pour le calcul du test φ* de Fisher pour identifier les différences dans les prévisions de deux groupes de médecins généralistes
Groupe | Il y a un effet - prévision de 41 à 100% | Aucun effet - prévision de 0 à 40 % | Total |
jegroupe - médecins qui ont pris le fonds | 26 (57.8%) | 19 (42.2%) | 45 |
IIgroupe - médecins qui n'ont pas pris le fonds | 9 (36.0%) | 16 (64.0%) | 25 |
Total | 35 | 35 | 70 |
Formulons des hypothèses.
H 0 : Pourcentage de personnesprédisant la distribution des fonds de 41% à 100% de toutes les réceptions médicales, dans le groupe des médecins disposant de fonds, il n'y en a pas plus que dans le groupe des médecins sans fonds.
H 1 : La proportion de personnes prédisant la distribution des fonds de 41% à 100% de toutes les réceptions dans le groupe des médecins disposant de fonds est supérieure à celle du groupe des médecins sans fonds.
Nous déterminons les valeurs de φ 1 et φ 2 selon le tableauXIIAnnexe 1. Rappelons que φ 1 est toujours l'angle correspondant au pourcentage le plus élevé.
Déterminons maintenant la valeur empirique du critère φ* :
Selon le tableau.XIIIL'annexe 1 détermine à quel niveau de signification correspond cette valeur : p=0,039.
Selon le même tableau en annexe 1, on peut déterminer les valeurs critiques du critère φ* :
Réponse: Mais rejeté (p=0,039). Pourcentage de personnes prédisant la distribution de fonds à41-100 % de l'ensemble des réceptionnistes, dans le groupe des médecins ayant pris la caisse, dépasse cette part dans le groupe des médecins n'ayant pas pris la caisse.
En d'autres termes, les médecins qui travaillent déjà dans leurs cabinets avec un budget séparé prévoient que cette pratique sera plus répandue cette année que les médecins qui n'ont pas encore accepté de passer à un budget séparé. Les interprétations de ce résultat sont multiples. Par exemple, on peut supposer que les médecins de chacun des groupes considèrent inconsciemment leur comportement comme plus typique. Cela pourrait également signifier que les médecins qui sont déjà passés à un budget autonome ont tendance à exagérer l'ampleur de ce mouvement, car ils doivent justifier leur décision. Les différences révélées peuvent également signifier quelque chose qui dépasse complètement le cadre des questions posées dans l'étude. Par exemple, que l'activité des médecins travaillant sur un budget indépendant contribue à accentuer les différences dans les positions des deux groupes. Ils ont été très actifs lorsqu'ils ont accepté de prendre les fonds, ils ont été très actifs lorsqu'ils ont pris la peine de répondre au questionnaire par courrier ; ils sont plus actifs lorsqu'ils prédisent que d'autres médecins seront plus actifs pour recevoir des fonds.
D'une manière ou d'une autre, nous pouvons être sûrs que le niveau des différences statistiques trouvées est le maximum possible pour ces données réelles. Nous avons établi à l'aide du critèreλ le point de divergence maximale entre les deux distributions, et c'est à ce point que les échantillons ont été divisés en deux parties.
Votre marque.







