Середнє квадратичне відхилення вбирається у. Середнє лінійне та середнє квадратичне відхилення
Стандартне відхилення є одним із тих статистичних термінівв корпоративному світі, що дозволяє підняти авторитет людей, які зуміли вдало ввернути його в ході бесіди чи презентації, і залишає невиразне непорозуміння тих, хто не знає, що це таке, але соромиться запитати. Насправді більшість менеджерів не розуміють концепцію стандартного відхилення і, якщо ви один із них, вам час перестати жити в брехні. У сьогоднішній статті я розповім вам, як цей недооцінений статистичний захід дозволить краще зрозуміти дані, з якими ви працюєте.
Що вимірює стандартне відхилення?
Уявіть, що ви є власником двох магазинів. І щоб уникнути втрат, важливо щоб був чіткий контроль залишків на складі. У спробі з'ясувати, хто з менеджерів краще управляє запасами, вирішили проаналізувати стоки останніх шести тижнів. Середня тижнева вартість стоку обох магазинів приблизно однакова і становить близько 32 умовних одиниць. На перший погляд, середнє значення стоку показує, що обидва менеджери працюють однаково.

Але якщо уважніше вивчити діяльність другого магазину, можна переконатись, що хоча середнє значення коректне, варіабельність стоку дуже висока (від 10 до 58 у.о.). Отже, можна дійти невтішного висновку, що середнє значення який завжди правильно оцінює дані. Ось де на допомогу приходить стандартне відхилення.
Стандартне відхилення показує, як розподілені значення щодо середнього у нашій . Іншими словами, можна зрозуміти наскільки великий розкид величини стоку від тижня до тижня.
У нашому прикладі ми скористалися функцією ExcelСТАНДОТКЛОН, щоб розрахувати показник стандартного відхилення разом із середнім.

У випадку з першим менеджером стандартне відхилення склало 2. Це говорить нам про те, що кожне значення у вибірці в середньому відкланяється на 2 від середнього значення. Чи це добре? Давайте розглянемо питання під іншим кутом - стандартне відхилення рівне 0, говорить нам про те, що кожне значення у вибірці дорівнює його середньому значенню (у нашому випадку, 32,2). Так, стандартне відхилення 2 трохи відрізняється від 0, і вказує на те, що більшість значень знаходяться поруч із середнім значенням. Чим ближче стандартне відхилення до 0, тим надійніше середнє. Більше того, стандартне відхилення близьке до 0 говорить про маленьку варіабельність даних. Тобто, величина стоку зі стандартним відхиленням 2 вказує на неймовірну послідовність першого менеджера.
У випадку з другим магазином стандартне відхилення склало 18,9. Тобто вартість стоку в середньому відхиляється на величину 18,9 від середнього від тижня до тижня. Божевільний розкид! Що далі стандартне відхилення від 0, то менш точно середнє значення. У нашому випадку цифра 18,9 вказує на те, що середньому значенню (32,8 у.о. на тиждень) просто не можна довіряти. Воно також говорить нам про те, що щотижнева величина стоку має велику варіабельність.
Така концепція стандартного відхилення двома словами. Хоча воно не дає уявлення про інші важливі статистичні виміри (Мода, Медіана…), фактично стандартне відхилення відіграє вирішальну роль більшості статистичних розрахунків. Розуміння принципів стандартного відхилення проллє світло на суть багатьох процесів вашої діяльності.
Як розрахувати стандартне відхилення?
Отже, тепер ми знаємо, про що свідчить цифра стандартного відхилення. Давайте розберемося, як вважається.
Розглянемо набір даних від 10 до 70 з кроком 10. Як бачите, я вже розрахував для них значення стандартного відхилення за допомогою функції СТАНДОТКЛОН у осередку H2 (помаранчевим).

Нижче описано кроки, які робить Excel, щоб прийти до цифри 21,6.
Зверніть увагу, що всі розрахунки візуалізовані для кращого розуміння. Насправді в Excel розрахунок відбувається миттєво, залишаючи всі кроки за лаштунками.
Спочатку Excel знаходить середнє значення вибірки. У нашому випадку середнє вийшло рівним 40, яке на наступному кроці віднімають від кожного значення вибірки. Кожну отриману різницю зводять у квадрат і підсумовують. У нас вийшла сума, що дорівнює 2800, яку необхідно розділити на кількість елементів вибірки мінус 1. Так як у нас 7 елементів, виходить необхідно 2800 розділити на 6. З отриманого результату знаходимо квадратний корінь, ця цифра буде стандартним відхиленням.

Для тих, кому не зрозумілий принцип розрахунку стандартного відхилення за допомогою візуалізації, наводжу математичну інтерпретацію знаходження даного значення.

Функції розрахунку стандартного відхилення в Excel
В Excel є кілька різновидів формул стандартного відхилення. Вам достатньо набрати = СТАНДОТКЛОН і ви самі в цьому переконаєтесь.

Варто зазначити, що функції СТАНДОТКЛОН.В та СТАНДОТКЛОН.Г (перша та друга функція у списку) дублюють функції СТАНДОТКЛОН та СТАНДОТКЛОНП (п'ята та шоста функція у списку), відповідно, які були залишені для сумісності з попередніми версіями.
Взагалі різниця в закінченнях.В і.Г функцій вказують на принцип розрахунку стандартного відхилення вибірки або генеральної сукупності. Різницю між двома цими масивами я вже пояснював у попередній.
Особливістю функцій СТАНДОТКЛОНУ та СТАНДОТКЛОНПУ (третя та четверта функція у списку), є те, що при розрахунку стандартного відхилення масиву в розрахунок приймаються логічні та текстові значення. Текстові та справжні логічні значення дорівнюють 1, а помилкові логічні значення дорівнюють 0. Мені важко уявити ситуацію, коли б мені могли знадобитися ці дві функції, тому, думаю, що їх можна ігнорувати.
Інструкція
Нехай є кілька чисел, що характеризують однорідні величини. Наприклад, результати вимірювань, зважувань, статистичних спостережень тощо. Усі представлені величини повинні вимірюватися однієї й тієї ж виміру. Щоб знайти квадратичне відхилення, виконайте такі дії.
Визначте середнє арифметичне всіх чисел: складіть усі числа та поділіть суму на Загальна кількістьчисел.
Визначте дисперсію (розкид) чисел: складіть квадрати знайдених раніше відхилень і поділіть отриману суму на кількість чисел.
У палаті лежать семеро хворих з температурою 34, 35, 36, 37, 38, 39 і 40 градусів Цельсія.
Потрібно визначити середнє відхилення від середньої.
Рішення:
"По палаті": (34 +35 +36 +37 +38 +39 +40) / 7 = 37 ºС;
Відхилення температур від середнього (у даному випадкунормального значення): 34-37, 35-37, 36-37, 37-37, 38-37, 39-37, 40-37, виходить: -3, -2, -1, 0, 1, 2, 3 (ºС);
Розділіть отриману ранню суму чисел їх кількість. Для точності обчислення краще скористатися калькулятором. Підсумок поділу є середнім арифметичним значенням доданків.
Уважно поставтеся до всіх етапів розрахунку, оскільки помилка хоч в одному з обчислень призведе до неправильного підсумкового показника. Перевіряйте отримані розрахунки кожному етапі. Середнє арифметичне число має той же вимірник, що й доданки, тобто якщо ви визначаєте середню відвідуваність, то всі показники у вас будуть «людина».
Цей спосібобчислення застосовується лише у математичних та статистичних розрахунках. Так, наприклад, середнього арифметичного значення інформатики має інший алгоритм обчислення. Середнє арифметичне значення дуже умовним показником. Воно показує можливість тієї чи іншої події за умови, що він лише один чинник чи показник. Для глибокого аналізу необхідно враховувати безліч чинників. І тому застосовується обчислення більш загальних величин.
Середнє арифметичне - один із заходів центральної тенденції, що широко використовується в математиці та статистичних розрахунках. Знайти середнє арифметичне число для кількох значень дуже просто, але у кожного завдання є свої нюанси, знати які для виконання вірних розрахунків просто необхідно.
Кількісні результати проведених подібних дослідів.
Як знайти середнє арифметичне число
Пошук середнього арифметичного числадля масиву чисел слід починати з визначення суми алгебри цих значень. Наприклад, якщо у масиві присутні числа 23, 43, 10, 74 і 34, їх алгебраїчна сума дорівнюватиме 184. При запису середнє арифметичне позначається буквою μ (мю) чи x (ікс з характеристикою). Далі суму алгебри слід розділити на кількість чисел в масиві. У аналізованому прикладі чисел було п'ять, тому середнє арифметичне дорівнюватиме 184/5 і становитиме 36,8.Особливості роботи з негативними числами
Якщо в масиві присутні негативні числа, Знаходження середнього арифметичного значення відбувається за аналогічним алгоритмом. Різниця є тільки при розрахунках у середовищі програмування, або якщо в задачі є додаткові умови. У цих випадках знаходження середнього арифметичного чисел з різними знакамизводиться до трьох дій:1. Знаходження загальної середньої арифметичної кількості стандартним методом;
2. Знаходження середнього арифметичного негативного числа.
3. Обчислення середнього арифметичного позитивного числа.
Відповіді кожної з дій записуються через кому.
Натуральні та десяткові дроби
Якщо масив чисел представлений десятковими дробами, Рішення відбувається за методом обчислення середнього арифметичного цілих чисел, але скорочення результату проводиться за вимогами завдання до точності відповіді.При роботі з натуральними дробамиїх слід призвести до спільному знаменникущо множиться на кількість чисел у масиві. У чисельнику відповіді буде сума наведених чисельників вихідних дробових елементів.
У цій статті я розповім про те, як знайти середньо квадратичне відхилення . Цей матеріал вкрай важливий для повноцінного розуміння математики, тому репетитор з математики повинен присвятити його вивченню окремого уроку або навіть кількох. У цій статті ви знайдете посилання на докладний і зрозумілий відеоурок, в якому розказано про те, що таке відхилення середньоквадратичне і як його знайти.
Середньоквадратичне відхиленнядає можливість оцінити розкид значень, отриманих у результаті виміру якогось параметра. Позначається символом (грецька буква "сигма").
Формула до розрахунку досить проста. Щоб знайти середньоквадратичне відхилення, потрібно взяти квадратне коріння з дисперсії. Тож тепер ви повинні запитати: "А що ж таке дисперсія?"
Що таке дисперсія
Визначення дисперсії звучить так. Дисперсія це середнє арифметичне від квадратів відхилень значень від середнього.
Щоб знайти дисперсію, послідовно проведіть такі обчислення:
- Визначте середнє (просте середнє арифметичне ряду значень).
- Потім від кожного зі значень відніміть середнє і зведіть отриману різницю в квадрат (отримали квадрат різниці).
- Наступним кроком буде обчислення середнього арифметичного отриманих квадратів різниць (чому саме квадратів ви зможете дізнатися нижче).
Розглянемо з прикладу. Допустимо, ви з друзями вирішили виміряти зростання ваших собак (у міліметрах). В результаті вимірів ви отримали такі дані вимірювань росту (в загривку): 600 мм, 470 мм, 170 мм, 430 мм і 300 мм.
Обчислимо середнє значення, дисперсію та середньоквадратичне відхилення.
Спочатку знайдемо середнє значення. Як ви вже знаєте, для цього потрібно скласти всі виміряні значення та поділити на кількість вимірів. Хід обчислень:
Середня мм.
Отже, середня (середньоарифметична) становить 394 мм.
Тепер потрібно визначити відхилення зростання кожного з собак від середнього:

Зрештою, щоб обчислити дисперсію, кожну з отриманих різниць зводимо в квадрат, а потім знаходимо середнє арифметичне від отриманих результатів:
Дисперсія мм 2 .
Таким чином, дисперсія становить 21 704 мм 2 .
Як знайти середньоквадратичне відхилення
То як же тепер вирахувати середньоквадратичне відхилення, знаючи дисперсію? Як ми пам'ятаємо, взяти із неї квадратний корінь. Тобто середньоквадратичне відхилення одно:
Мм (округлено до найближчого цілого значення мм).
Застосувавши цей метод, ми з'ясували, що деякі собаки (наприклад, ротвейлери) дуже великі собаки. Але є й дуже маленькі собаки (наприклад, такси, тільки казати їм цього не варто).
Найцікавіше, що середньоквадратичне відхилення несе у собі корисну інформацію. Тепер ми можемо показати, які з отриманих результатів вимірювання зростання знаходяться в межах інтервалу, який ми отримаємо, якщо відкладемо від середнього (в обидва боки від нього) середньоквадратичне відхилення.
Тобто за допомогою середньоквадратичного відхилення ми отримуємо "стандартний" метод, який дозволяє дізнатися, яке із значень є нормальним (середньостатистичним), а яке екстраординарно більшим або, навпаки, малим.
Що таке стандартне відхилення
Але… все буде трохи інакше, якщо ми аналізуватимемо вибіркуданих. У нашому прикладі ми розглядали генеральну сукупність.Тобто наші 5 собак були єдиними у світі собаками, які нас цікавили.
Але якщо дані є вибіркою (значеннями, які обрали із великої генеральної сукупності), тоді обчислення потрібно вести інакше.
Якщо є значень, то:
Всі інші розрахунки проводяться аналогічно, зокрема визначення середнього.
Наприклад, якщо наших п'ять собак – лише вибірка з генеральної сукупності собак (всіх собак на планеті), ми маємо ділити на 4, а не на 5,а саме:
Дисперсія вибірки =  мм 2 .
мм 2 .
При цьому стандартне відхилення щодо вибірки дорівнює  мм (округлено до найближчого цілого значення).
мм (округлено до найближчого цілого значення).
Можна сказати, що ми зробили деяку “корекцію” у випадку, коли наші значення є лише невеликою вибіркою.
Примітка. Чому саме квадрати різниць?
Але чому при обчисленні дисперсії ми беремо квадрати різниць? Допустимо при вимірі якогось параметра, ви отримали наступний набір значень: 4; 4; -4; -4. Якщо ми просто складемо абсолютні відхилення від середнього (різниці) між собою. від'ємні значеннявзаємно знищаться з позитивними:
 .
.
Виходить, цей варіант марний. Тоді, можливо, варто спробувати абсолютні значення відхилень (тобто модулі цих значень)?
На перший погляд виходить непогано (отримана величина, до речі, називається середнім абсолютним відхиленням), але не у всіх випадках. Спробуємо інший приклад. Нехай у результаті виміру вийшов наступний набір значень: 7; 1; -6; -2. Тоді середнє абсолютне відхилення одно:
Ось це так! Знов отримали результат 4, хоча різниці мають набагато більший розкид.
А тепер подивимося, що вийде, якщо звести різниці у квадрат (і взяти потім квадратний корінь із їхньої суми).
Для першого прикладу вийде:
 .
.
Для другого прикладу вийде:
Тепер – зовсім інша річ! Середньоквадратичне відхилення виходить тим більшим, чим більший розкид мають різниці ... чого ми і прагнули.
Фактично в даному методівикористана та сама ідея, що й під час обчислення відстані між точками, лише застосована іншим способом.
І з математичної точки зору використання квадратів і квадратного коріннядає більше користі, ніж ми могли б отримати на підставі абсолютних значень відхилень, завдяки чому середньоквадратичне відхилення можна застосувати і для інших математичних завдань.
Про те, як знайти середньоквадратичне відхилення, вам розповів , Сергій Валерійович
$X$. Для початку нагадаємо таке визначення:
Визначення 1
Генеральна сукупність- Сукупність випадково відібраних об'єктів даного виду, над якими проводять спостереження з метою отримання конкретних значень випадкової величини, що проводяться в незмінних умовах щодо однієї випадкової величини даного виду.
Визначення 2
Генеральна дисперсія-- середнє арифметичне квадратів відхилень значень варіант генеральної сукупності від їхнього середнього значення.
Нехай значення варіант $x_1, \ x_2, \ dots, x_k $ мають, відповідно, частоти $ n_1, \ n_2, \ dots, n_k $. Тоді генеральна дисперсія обчислюється за такою формулою:
Розглянемо окремий випадок. Нехай всі варіанти $ x_1, \ x_2, \ dots, x_k $ різні. У цьому випадку $n_1, \ n_2, \ dots, n_k = 1 $. Отримуємо, що у цьому випадку генеральна дисперсія обчислюється за такою формулою:
З цим поняттям також пов'язане поняття генерального середнього відхилення квадратичного.
Визначення 3
Генеральне середнє квадратичне відхилення
\[(\sigma)_г=\sqrt(D_г)\]
Вибіркова дисперсія
Нехай нам дано вибіркову сукупність щодо випадкової величини $X$. Для початку нагадаємо таке визначення:
Визначення 4
Вибіркова сукупність- частина відібраних об'єктів із генеральної сукупності.
Визначення 5
Вибіркова дисперсія- середнє арифметичне значеньваріант вибіркової сукупності.
Нехай значення варіант $x_1, \ x_2, \ dots, x_k $ мають, відповідно, частоти $ n_1, \ n_2, \ dots, n_k $. Тоді вибіркова дисперсія обчислюється за такою формулою:
Розглянемо окремий випадок. Нехай всі варіанти $ x_1, \ x_2, \ dots, x_k $ різні. У цьому випадку $n_1, \ n_2, \ dots, n_k = 1 $. Отримуємо, що у цьому випадку вибіркова дисперсія обчислюється за такою формулою:
З цим поняттям пов'язане поняття вибіркового середнього квадратичного відхилення.
Визначення 6
Вибіркове середнє квадратичне відхилення- Квадратний корінь з генеральної дисперсії:
\[(\sigma )_в=\sqrt(D_в)\]
Виправлена дисперсія
Для знаходження виправленої дисперсії $S^2$ необхідно помножити вибіркову дисперсію на дріб $\frac(n)(n-1)$, тобто
З цим поняттям також пов'язане поняття виправленого середнього квадратичного відхилення, яке знаходиться за формулою:
У разі, коли значення варіант не є дискретними, а являють собою інтервали, то в формулах для обчислення генеральної або вибіркової дисперсій за значення $x_i$ приймається значення середини інтервалу, якому належить $x_i.$
Приклад завдання на знаходження дисперсії та середнього квадратичного відхилення
Приклад 1
Вибіркова сукупність задана наступною таблицею розподілу:
Малюнок 1.
Знайдемо для неї вибіркову дисперсію, вибіркове середнє квадратичне відхилення, виправлену дисперсію та виправлене середнє квадратичне відхилення.
Для вирішення цього завдання для початку зробимо розрахункову таблицю:
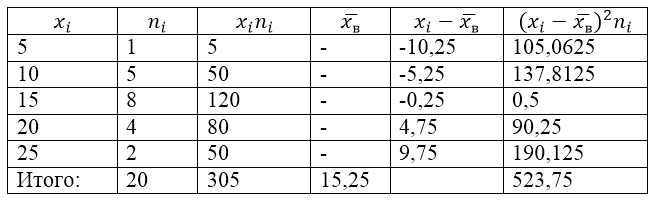
Малюнок 2.
Величина $\overline(x_в)$ (середнє вибіркове) у таблиці знаходиться за формулою:
\[\overline(x_в)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_в)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15,25\]
Знайдемо вибіркову дисперсію за формулою:
Вибіркове середнє квадратичне відхилення:
\[(\sigma)_в=\sqrt(D_в)\approx 5,12\]
Виправлена дисперсія:
\[(S^2=\frac(n)(n-1)D)_в=\frac(20)(19)\cdot 26,1875\approx 27,57\]
Виправлене середнє квадратичне відхилення.
Найбільш досконалою характеристикою варіації є середнє квадратичне відкладення, яке називають стандартом (або стандартним відхиленням). Середнє квадратичне відхилення() дорівнює квадратному кореню із середнього квадрата відхилень окремих значень ознаки від середньої арифметичної:
Середнє квадратичне відхилення просте:


Середнє зважене квадратичне відхилення застосовується для згрупованих даних:

Між середнім квадратичним та середнім лінійним відхиленнямив умовах нормального розподілумає місце таке співвідношення: ~ 1,25.
Середнє квадратичне відхилення, будучи основною абсолютною мірою варіації, використовується щодо значень ординат кривої нормального розподілу, у розрахунках, пов'язаних з організацією вибіркового спостереження та встановленням точності вибіркових характеристик, і навіть в оцінці меж варіації ознаки в однорідної сукупності.
Дисперсія, її види, середньоквадратичне відхилення.
Дисперсія випадкової величини- міра розкиду цієї випадкової величини, тобто її відхилення від математичного очікування. У статистиці часто використовується позначення чи . Квадратний коріньз дисперсії називається середньоквадратичним відхиленням, стандартним відхиленням або стандартним розкидом.
Загальна дисперсія (σ 2) вимірює варіацію ознаки у всій сукупності під впливом всіх факторів, що зумовили цю варіацію. Разом з тим, завдяки методу угруповань можна виділити та виміряти варіацію, зумовлену групувальною ознакою, та варіацію, що виникає під впливом неврахованих факторів.
Міжгрупова дисперсія (σ 2 м.гр) характеризує систематичну варіацію, тобто відмінності у величині досліджуваної ознаки, що виникають під впливом ознаки - фактора, покладеного в основу угруповання.
Середньоквадратичне відхилення(синоніми: середнє квадратичне відхилення, середньоквадратичне відхилення, Квадратичне відхилення; близькі терміни: стандартне відхилення, стандартний розкид) — теоретично ймовірностей і статистиці найпоширеніший показник розсіювання значень випадкової величини щодо її математичного очікування. При обмежених масивах вибірок значень замість математичного очікування використовується середнє арифметичне сукупності вибірок.
Середньоквадратичне відхилення вимірюється в одиницях виміру випадкової величини і використовується при розрахунку стандартної помилкисереднього арифметичного, при побудові довірчих інтервалів, при статистичній перевірці гіпотез, при вимірі лінійного взаємозв'язку між випадковими величинами. Визначається як квадратний корінь з дисперсії випадкової величини.
Середньоквадратичне відхилення:

Стандартне відхилення(Оцінка середньоквадратичного відхилення випадкової величини xщодо її математичного очікування на основі незміщеної оцінки її дисперсії):

де - Дисперсія; - i-й елемент вибірки; - Обсяг вибірки; - Середнє арифметичне вибірки:
![]()
Слід зазначити, що обидві оцінки є зміщеними. У загальному випадкунезміщену оцінку збудувати неможливо. Проте оцінка з урахуванням оцінки несмещенной дисперсії є заможною.
Сутність, сфера застосування та порядок визначення моди та медіани.
Крім статечних середніх у статистиці для відносної характеристики величини варіює ознаки і внутрішньої будовирядів розподілу користуються структурними середніми, які представлені, переважно, модою та медіаною.
Мода— це варіант ряду, що найчастіше зустрічається. Мода застосовується, наприклад, щодо розміру одягу, взуття, що користується найбільшим попитом у покупців. Модою для дискретного ряду є варіанта, що має найбільшу частоту. При обчисленні моди для інтервального варіаційного рядунеобхідно спочатку визначити модальний інтервал (за максимальною частотою), а потім значення модальної величини ознаки за формулою:

- - Значення моди
- - нижня межа модального інтервалу
- - Величина інтервалу
- - Частота модального інтервалу
- - Частота інтервалу, що передує модальному
- - Частота інтервалу, наступного за модальним
Медіанаце значення ознаки, що лежить в основі ранжованого ряду та ділить цей ряд на дві рівні за чисельністю частини.
Для визначення медіани в дискретному рядуза наявності частот спочатку обчислюють напівсуму частот , та був визначають, яке значення варіанта посідає неї. (Якщо відсортований ряд містить непарну кількість ознак, то номер медіани обчислюють за формулою:
М е = (n (число ознак у сукупності) + 1)/2,
у разі парного числа ознак медіана дорівнюватиме середньої з двох ознак що знаходяться в середині ряду).
При обчисленні медіанидля інтервального варіаційного ряду спочатку визначають медіанний інтервал, в межах якого знаходиться медіана, а потім значення медіани за формулою:

- - Шукана медіана
- нижня межа інтервалу, який містить медіану
- - Величина інтервалу
- - Сума частот або число членів ряду
Сума накопичених частот інтервалів, що передують медіанному
- - Частота медіанного інтервалу
приклад. Знайти моду та медіану.
Рішення:
У даному прикладімодальний інтервал перебуває у межах вікової групи 25-30 років, оскільки цей інтервал припадає максимальна частота (1054).
Розрахуємо величину моди:
Це означає, що модальний вік студентів дорівнює 27 рокам.
Обчислимо медіану. Медіанний інтервал знаходиться у віковій групі 25-30 років, тому що в межах цього інтервалу розташована варіанта, яка поділяє сукупність на дві рівні частини (?f i/2=3462/2=1731). Далі підставляємо у формулу необхідні числові дані та отримуємо значення медіани:

Це означає, що одна половина студентів має вік до 27,4 року, а інша понад 27,4 роки.
Крім моди і медіани можуть бути використані такі показники, як квартилі, що ділять ранжований ряд на 4 рівні частини, децилі- 10 частин та перцентілі – на 100 частин.
Поняття вибіркового спостереження та сфера його застосування.
Вибіркове спостереженнязастосовується, коли застосування суцільного спостереження фізично неможливочерез великий масив даних або економічно недоцільно. Фізична неможливість має місце, наприклад, щодо пасажиропотоків, ринкових цін, сімейних бюджетів. Економічна недоцільність має місце в оцінці якості товарів, що з їх знищенням, наприклад, дегустація, випробування цегли на міцність тощо.
Статистичні одиниці, відібрані для спостереження, становлять вибіркову сукупність чи вибірку, а їх масив - генеральну сукупність (ГС). При цьому число одиниць у вибірці позначають n, а у всій ГС - N. Ставлення n/Nназивається відносний розмір або частка вибірки.
Якість результатів вибіркового спостереження залежить від репрезентативності вибірки, тобто від цього, наскільки вона представницька в ГС. Для забезпечення репрезентативності вибірки необхідно дотримуватись принцип випадковості відбору одиниць, який передбачає, що у включення одиниці ГС у вибірку неспроможна вплинути якийсь інший чинник крім випадку.
Існує 4 способи випадкового відборуу вибірку:
- Власне випадковийвідбір чи «метод лото», коли статистичним величинам надаються порядкові номери, що заносяться на певні предмети (наприклад, барильця), які потім перемішуються в деякій ємності (наприклад, в мішку) і вибираються навмання. Насправді цей спосіб здійснюють за допомогою генератора випадкових чисел або математичних таблиць випадкових чисел.
- Механічнийвідбір, за яким відбирається кожна ( N/n)-я величина генеральної сукупності. Наприклад, якщо вона містить 100 000 величин, а потрібно вибрати 1 000, то вибірку потрапить кожна 100 000 / 1000 = 100-а величина. Причому якщо вони не ранжовані, то перша вибирається навмання з першої сотні, а номери інших будуть на сотню більше. Наприклад, якщо першою виявилася одиниця № 19, то наступною має бути № 119, потім № 219, потім № 319 тощо. Якщо одиниці генеральної сукупності ранжовані, то першою вибирається № 50, потім № 150, потім № 250 і таке інше.
- Відбір величин із неоднорідного масиву даних ведеться стратифікованим(Розшарованим) способом, коли генеральна сукупність попередньо розбивається на однорідні групи, до яких застосовується випадковий або механічний відбір.
- Особливий спосіб складання вибірки є серійнийвідбір, у якому випадково чи механічно вибирають окремі величини, які серії (послідовності з якогось номера за якийсь поспіль), всередині яких ведуть суцільне спостереження.
Якість вибіркових спостережень залежить і від типу вибірки: повторнаабо безповторна.
При повторному відборістатистичні величини, що потрапили у вибірку, або їх серії після використання повертаються в генеральну сукупність, маючи шанс потрапити в нову вибірку. При цьому у всіх величин генеральної сукупності однакова можливість включення у вибірку.
Неповторний відбірозначає, що статистичні величини, що потрапили у вибірку, або їх серії після використання не повертаються в генеральну сукупність, а тому для інших величин останньої підвищується ймовірність потрапляння в наступну вибірку.
Безповторний відбір дає більше точні результатитому застосовується частіше. Але є ситуації, коли його не можна застосувати (вивчення пасажиропотоків, споживчого попиту тощо) і тоді ведеться повторний відбір.
Гранична помилка вибірки спостереження, середня помилка вибірки, порядок їхнього розрахунку.
Розглянемо докладно перелічені вище способи формування вибіркової сукупності і помилки, що виникають при цьому. репрезентативності .
Власне-випадковаВибірка ґрунтується на відборі одиниць з генеральної сукупності навмання без будь-яких елементів системності. Технічно власне-випадковий відбір проводять методом жеребкування (наприклад, розіграші лотерей) або таблицею випадкових чисел.
Власно-випадковий відбір чистому вигляді» у практиці вибіркового спостереження застосовується рідко, але він є вихідним серед інших видів відбору, у ньому реалізуються основні засади вибіркового спостереження. Розглянемо деякі питання теорії вибіркового методу та формули помилок для простої випадкової вибірки.
Помилка вибіркового спостереження- це різницю між величиною параметра у генеральній сукупності, та її величиною, обчисленої за результатами вибіркового спостереження. Для середньої кількісної ознаки помилка вибірки визначається
Показник називається граничною помилкою вибірки.
Вибіркова середня є випадковою величиною, яка може приймати різні значенняв залежності від того, які одиниці потрапили у вибірку. Отже, помилки вибірки є випадковими величинами і можуть приймати різні значення. Тому визначають середню з можливих помилок - середню помилку вибірки, яка залежить від:
Об'єм вибірки: чим більша чисельність, тим менша величина середньої помилки;
Ступені зміни ознаки, що вивчається: чим менше варіація ознаки, а, отже, і дисперсія, тим менше середня помилкавибірки.
При випадковому повторному відборісередня помилка розраховується:
.
Практично генеральна дисперсія точно не відома, але в теорії ймовірностідоведено, що ![]() .
.
Оскільки величина за досить великих n близька до 1, вважатимуться, що . Тоді середня помилка вибірки може бути розрахована:
.
Але у випадках малої вибірки (при n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
При випадковій безповторній вибірцінаведені формули коригуються на величину. Тоді середня помилка безповторної вибірки:  і
і  .
.
Т.к. завжди менше, то множник () завжди менше 1. Це означає, що середня помилка при безповторному відборі завжди менше, ніж при повторному.
Механічна вибірказастосовується, коли генеральна сукупність у будь-який спосіб упорядкована (наприклад, списки виборців за алфавітом, телефонні номери, номери будинків, квартир). Відбір одиниць здійснюється через певний інтервал, що дорівнює зворотному значенню відсотка вибірки. Так за 2% вибірці відбирається кожна 50 одиниця =1/0,02 , при 5% кожна 1/0,05=20 одиниця генеральної сукупності.
Початок відліку вибирається різними способами: випадковим чином, із середини інтервалу, зі зміною початку відліку. Головне при цьому – уникнути систематичної помилки. Наприклад, при 5% вибірці, якщо першою одиницею обрано 13-ту, то наступні 33, 53, 73 і т.д.
За точністю механічний відбір близький до власно-випадкової вибірки. Тому визначення середньої помилки механічної вибірки використовують формули власне-випадкового відбору.
При типовому відборі обстежувана сукупність попередньо розбивається на однорідні, однотипні групи. Наприклад, при обстеженні підприємств це можуть бути галузі, підгалузі, щодо населення - райони, соціальні чи вікові групи. Потім здійснюється незалежний вибір із кожної групи механічним або власне-випадковим способом.
Типова вибірка дає більш точні результати проти іншими способами. Типізація генеральної сукупності забезпечує представництво у вибірці кожної типологічної групи, що дозволяє виключити вплив міжгрупової дисперсії на середню помилку вибірки. Отже, при знаходженні помилки типової вибірки відповідно до правила складання дисперсій необхідно врахувати лише середню з групових дисперсій. Тоді середня помилка вибірки:
при повторному відборі
,
при безповторному відборі  ,
,
де  - Середня із внутрішньогрупових дисперсій у вибірці.
- Середня із внутрішньогрупових дисперсій у вибірці.
Серійний (або гніздовий) відбір
застосовується у разі, коли генеральна сукупність розбита на серії чи групи на початок вибіркового обстеження. Цими серіями можуть бути упаковки готової продукції, студентські групи, бригади. Серії для обстеження вибираються механічним чи власне-випадковим способом, а всередині серії проводиться суцільне обстеження одиниць. Тому середня помилка вибірки залежить лише від міжгрупової (міжсерійної) дисперсії, яка обчислюється за такою формулою: 
де r – число відібраних серій;
- середня і-та серія.
Середня помилка серійної вибірки розраховується:
при повторному відборі:
,
при безповторному відборі:  ,
,
де R – загальна кількість серій.
Комбінованийвідбірє поєднанням розглянутих способів відбору.
Середня помилка вибірки за будь-якого способу відбору залежить головним чином абсолютної чисельності вибірки й у меншою мірою - від відсотка вибірки. Припустимо, що проводиться 225 спостережень у першому випадку з генеральної сукупності 4500 одиниць і у другому - 225000 одиниць. Дисперсії в обох випадках дорівнюють 25. Тоді в першому випадку при 5% відборі помилка вибірки складе: 
У другому випадку при 0,1% відборі вона дорівнюватиме:

Таким чином, при зменшенні відсотка вибірки у 50 разів, помилка вибірки збільшилася незначно, оскільки чисельність вибірки не змінилася.
Припустимо, що кількість вибірки збільшили до 625 спостережень. У цьому випадку помилка вибірки дорівнює: 
Збільшення вибірки в 2,8 разу за однієї й тієї ж чисельності генеральної сукупності знижує розміри помилки вибірки більш як 1,6 разу.
Методи та способи формування вибіркової сукупності.
У статистиці застосовуються різні способи формування вибіркових сукупностей, що обумовлюється завданнями дослідження та залежить від специфіки об'єкта вивчення.
Основною умовою проведення вибіркового обстеження є запобігання виникненню систематичних помилок, що виникають внаслідок порушення принципу рівних можливостей потрапляння у вибірку кожної одиниці генеральної сукупності. Попередження систематичних помилок досягається внаслідок застосування науково обґрунтованих способів формування вибіркової сукупності.
Існують такі способи відбору одиниць із генеральної сукупності:
1) індивідуальний відбір - у вибірку відбираються окремі одиниці;
2) груповий відбір - у вибірку потрапляють якісно однорідні групи або серії одиниць, що вивчаються;
3) комбінований відбір - це комбінація індивідуального та групового відбору.
Способи відбору визначаються правилами формування вибіркової сукупності.
Вибірка може бути:
- власне-випадковаполягає в тому, що вибіркова сукупність утворюється в результаті випадкового (ненавмисного) відбору окремих одиниць із генеральної сукупності. При цьому кількість відібраних у вибіркову сукупність одиниць зазвичай визначається, виходячи з прийнятої частки вибірки. Частка вибірки є відношення числа одиниць вибіркової сукупності n чисельності одиниць генеральної сукупності N, тобто.
- механічнаполягає в тому, що відбір одиниць у вибіркову сукупність виробляється з генеральної сукупності, розбитої на рівні інтервали (групи). При цьому розмір інтервалу в генеральній сукупності дорівнює зворотній величині частки вибірки. Так, при 2% вибірці відбирається кожна 50-а одиниця (1:0,02), при 5% вибірці - кожна 20 одиниця (1:0,05) і т.д. Таким чином, відповідно до прийнятої частки відбору, генеральна сукупність механічно розбивається на рівновеликі групи. З кожної групи у вибірку відбирається лише одна одиниця.
- типова -при якій генеральна сукупність спочатку розчленовується на однорідні типові групи. Потім із кожної типової групи власне-випадковою або механічною вибіркою проводиться індивідуальний відбір одиниць у вибіркову сукупність. Важливою особливістю типової вибірки і те, що вона дає точніші результати проти іншими способами відбору одиниць у вибіркову сукупність;
- серійна- за якої генеральну сукупність ділять на однакові за обсягом групи - серії. У вибіркову сукупність відбираються серії. Усередині серій проводиться суцільне спостереження одиниць, що потрапили до серії;
- комбінована- вибірка може бути двоступінчастою. У цьому генеральна сукупність спочатку розбивається групи. Потім здійснюють відбір груп, а всередині останніх здійснюється відбір окремих одиниць.
У статистиці розрізняють такі способи відбору одиниць у вибіркову сукупність:
- одноступінчаставибірка - кожна відібрана одиниця відразу ж піддається вивченню за заданою ознакою (власне-випадкова та серійна вибірки);
- багатоступінчаставибірка - виробляють підбір з генеральної сукупності окремих груп, та якщо з груп вибираються окремі одиниці (типова вибірка з механічним способом відбору одиниць у вибіркову сукупність).
Крім того розрізняють:
- повторний відбір- За схемою повернутої кулі. При цьому кожна одиниця, що потрапила у вибірку, іди серія повертається в генеральну сукупність і тому має шанс знову потрапити у вибірку;
- безповторний відбір- За схемою неповернутої кулі. Він має більш точні результати при тому самому обсязі вибірки.
Визначення необхідного обсягу вибірки (використання таблиці Стьюдента).
Одним із наукових принципів у теорії вибіркового методу є забезпечення достатньої кількості відібраних одиниць. Теоретично необхідність дотримання цього принципу представлена в доказах граничних теорем теорії ймовірностей, які дозволяють встановити, який обсяг одиниць слід вибрати з генеральної сукупності, щоб він був достатнім та забезпечував репрезентативність вибірки.
Зменшення стандартної помилки вибірки, а отже, збільшення точності оцінки завжди пов'язане зі збільшенням обсягу вибірки, тому вже на стадії організації вибіркового спостереження доводиться вирішувати питання про те, яким має бути обсяг вибіркової сукупності, щоб була забезпечена необхідна точність результатів спостережень. Розрахунок необхідного обсягу вибірки будується за допомогою формул, виведених з формул граничних помилок вибірки (А), відповідних тому чи іншому виду та способу відбору. Так, для випадкового повторного обсягу вибірки (n) маємо:

Суть цієї формули - у цьому, що з випадковому повторному відборі необхідної чисельності обсяг вибірки прямо пропорційний квадрату коефіцієнта довіри (t2)і дисперсії варіаційної ознаки (?2) і обернено пропорційний квадрату граничної помилки вибірки (?2). Зокрема, зі збільшенням граничної помилки вдвічі необхідна чисельність вибірки може бути зменшена вчетверо. З трьох параметрів два (t і ?) задаються дослідником.
При цьому дослідник виходячиз метою завдань вибіркового обстеження має вирішити питання: у якому кількісному поєднанні краще включити ці параметри для забезпечення оптимального варіанту? В одному випадку його може більше влаштовувати надійність отриманих результатів (t), ніж міра точності (?), В іншому - навпаки. Складніше вирішити питання щодо величини граничної помилки вибірки, тому що цим показником дослідник на стадії проектування вибіркового спостереження не має, тому в практиці прийнято ставити величину граничної помилки вибірки, як правило, в межах до 10% передбачуваного середнього рівня ознаки. До встановлення передбачуваного середнього рівня можна підходити по-різному: використовувати дані подібних раніше проведених обстежень або скористатися даними основи вибірки і зробити невелику пробну вибірку.
Найбільш складно встановити під час проектування вибіркового спостереження третій параметр у формулі (5.2) - дисперсію вибіркової сукупності. У цьому випадку необхідно використовувати всю інформацію, що є у розпорядженні дослідника, отриману в раніше проведених подібних та пробних обстеженнях.
Питання визначеннянеобхідної чисельності вибірки ускладнюється, якщо вибіркове обстеження передбачає вивчення кількох ознак одиниць відбору. У цьому випадку середні рівні кожної з ознак та їх варіація, як правило, різні, і тому вирішити питання про те, дисперсії якої з ознак віддати перевагу, можливо лише з урахуванням мети та завдань обстеження.
При проектуванні вибіркового спостереження передбачаються заздалегідь задана величина припустимої помилки вибірки відповідно до завдань конкретного дослідження та ймовірність висновків за результатами спостереження.
Загалом формула граничної помилки вибіркової середньої величини дозволяє визначати:
Величину можливих відхилень показників генеральної сукупності від показників вибіркової сукупності;
Необхідну чисельність вибірки, що забезпечує необхідну точність, коли межі можливої помилки не перевищать деякої заданої величини;
Імовірність того, що у проведеній вибірці помилка матиме задану межу.
Розподіл Стьюдентатеоретично ймовірностей — це однопараметричне сімейство абсолютно безперервних розподілів.
Ряди динаміки (інтервальні, моментні), змикання рядів динаміки.
Ряди динаміки- це значення статистичних показників, які представлені у певній хронологічній послідовності.
Кожен динамічний ряд містить дві складові:
1) показники періодів часу (роки, квартали, місяці, дні чи дати);
2) показники, що характеризують об'єкт, що досліджується, за тимчасові періоди або на відповідні дати, які називають рівнями ряду.
Рівні ряду виражаютьсяяк абсолютними, і середніми чи відносними величинами. Залежно від характеру показників будують динамічні ряди абсолютних, відносних та середніх величин. Ряди динаміки з відносних та середніх величин будують на основі похідних рядів абсолютних величин. Розрізняють інтервальні та моментні ряди динаміки.
Динамічний інтервальний рядмістить значення показників за певний період часу. В інтервальному ряду рівні можна підсумовувати, одержуючи обсяг явища за триваліший період, або звані накопичені результати.
Динамічний моментний рядвідбиває значення показників на певний час (дату часу). У моментних рядах дослідника може цікавити лише різницю явищ, що відбиває зміна рівня низки між певними датами, оскільки сума рівнів тут немає реального змісту. Накопичені результати тут не розраховуються.
Найважливішою умовою правильної побудови динамічних рядів є сумісність рівнів рядів, що належать до різних періодів. Рівні повинні бути представлені в однорідних величинах, повинна мати місце однакова повнота охоплення різних частин явища.
Для того щобуникнути спотворення реальної динаміки; у статистичному дослідженні проводяться попередні розрахунки (змикання рядів динаміки), які передують статистичному аналізу динамічних рядів. Під змиканням рядів динаміки розуміється об'єднання до одного ряду двох і більше рядів, рівні яких розраховані за різною методологією або не відповідають територіальним кордонам тощо. Змикання рядів динаміки може припускати також приведення абсолютних рівнів рядів динаміки до загальної основи, що нівелює непорівнянність рівнів динаміки.
Поняття сумісності рядів динаміки, коефіцієнти, темпи зростання та приросту.
Ряди динаміки- Це ряди статистичних показників, що характеризують розвиток явищ природи та суспільства в часі. Статистичні збірники, що публікуються Держкомстатом Росії, містять велику кількість рядів динаміки в табличній формі. Ряди динаміки дозволяють виявити закономірності розвитку явищ, що вивчаються.
Ряди динаміки містять два види показників. Показники часу(Роки, квартали, місяці та ін) або моменти часу (на початок року, на початок кожного місяця і т.п.). Показники рівнів ряду. Показники рівнів рядів динаміки можуть бути виражені абсолютними величинами (виробництво продукту в тоннах або рублях), відносними величинами (питома вага міського населення у %) та середніми величинами (середня заробітна плата працівників галузі за роками тощо). У табличній формі ряд динаміки містить два стовпці або два рядки.
Правильне побудова рядів динаміки передбачає виконання низки вимог:
- усі показники низки динаміки мають бути науково обґрунтованими, достовірними;
- показники низки динаміки мають бути зіставні за часом, тобто. мають бути обчислені за однакові періоди часу чи однакові дати;
- показники низки динаміки мають бути зіставні територією;
- показники низки динаміки мають бути зіставні за змістом, тобто. обчислені за єдиною методологією, однаковим способом;
- показники низки динаміки мають бути зіставні по колу господарств, що враховуються. Усі показники низки динаміки повинні бути наведені в одних і тих самих одиницях вимірювання.
Статистичні показникиможуть характеризувати або результати досліджуваного процесу у період, або стан досліджуваного явища певний час, тобто. показники можуть бути інтервальними (періодичними) та моментними. Відповідно спочатку ряди динаміки можуть бути або інтервальними, або моментними. Моментні ряди динаміки у свою чергу можуть бути з рівними та нерівними проміжками часу.
Початкові ряди динаміки можуть бути перетворені на ряд середніх величин і ряд відносних величин (ланцюговий та базисний). Такі ряди динаміки називають похідними рядами динаміки.
Методика розрахунку середнього рівня серед динаміки різна, обумовлена виглядом низки динаміки. На прикладах розглянемо види рядів динаміки та формули для розрахунку середнього рівня.
Абсолютні прирости (Δy) показують, наскільки одиниць змінився наступний рівень ряду порівняно з попереднім (гр.3 - ланцюгові абсолютні прирости) або в порівнянні з початковим рівнем (гр.4 - базисні абсолютні прирости). Формули розрахунку можна записати так:

При зменшенні абсолютних значень ряду буде відповідно "зменшення", "зниження".
Показники абсолютного приросту свідчать, що, наприклад, 1998 р. виробництво продукту " А " збільшилося проти 1997 р. на 4 тис. т, а проти 1994 р. — на 34 тис. т.; за рештою років див. табл. 11.5 гр. 3 та 4.
Коефіцієнт зростанняпоказує, скільки разів змінився рівень низки проти попереднім (гр.5 — ланцюгові коефіцієнти зростання чи зниження) чи порівняно з початковим рівнем (гр.6 — базисні коефіцієнти зростання чи зниження). Формули розрахунку можна записати так:

Темпи зростанняпоказують, скільки відсотків становить наступний рівень низки проти попереднім (гр.7 — ланцюгові темпи зростання) чи проти початковим рівнем (гр.8 — базисні темпи зростання). Формули розрахунку можна записати так:

Приміром, 1997 р. обсяги виробництва продукту " А " проти 1996 р. становив 105,5 % (
Темпи прироступоказують, скільки відсотків збільшився рівень звітного періоду проти попереднім (гр.9- ланцюгові темпи приросту) чи проти початковим рівнем (гр.10- базисні темпи приросту). Формули розрахунку можна записати так:
Т пр = Т р - 100% або Т пр = абсолютний приріст / рівень попереднього періоду * 100%
Приміром, 1996 р. проти 1995 р. продукту " А " вироблено більше на 3,8 % (103,8 %- 100%) чи (8:210)х100%, а проти 1994 р. - на 9% (109% - 100%).
Якщо абсолютні рівні в ряду зменшуються, то темп буде меншим за 100% і відповідно буде темп зниження (темп приросту зі знаком мінус).
Абсолютне значення 1% приросту(Гр. 11) показує, скільки одиниць треба зробити в даному періоді, щоб рівень попереднього періоду зріс на 1%. У прикладі, 1995 р. треба було виробити 2,0 тис. т., а 1998 р. — 2,3 тис. т., тобто. значно більше.
Визначити величину абсолютного значення 1% приросту можна двома способами:
Рівень попереднього періоду поділити на 100;
Ланцюгові абсолютні прирости розділити на відповідні ланцюгові темпи приросту.
Абсолютне значення 1% приросту = 
У динаміці, особливо протягом тривалого періоду, важливий спільний аналіз темпів приросту зі змістом кожного відсотка приросту чи зниження.
Зауважимо, що розглянута методика аналізу рядів динаміки застосовна як для рядів динаміки, рівні яких виражені абсолютними величинами (т, тис. руб., Число працівників і т.д.), так і для рядів динаміки, рівні яких виражені відносними показниками (% шлюбу ,% зольності вугілля та ін) або середніми величинами (середня врожайність у ц/га, середня заробітна плата тощо).
Поряд із розглянутими аналітичними показниками, що обчислюються за кожен рік у порівнянні з попереднім або початковим рівнем, при аналізі рядів динаміки необхідно обчислити середні за період аналітичні показники: середній рівень ряду, середній річний абсолютний приріст (зменшення) та середній річний темп зростання та темп приросту.
Методи розрахунку середнього рівня низки динаміки було розглянуто вище. У аналізованому нами інтервальному ряду динаміки середній рівень ряду обчислюється за формулою середньої арифметичної простий:
Середньорічний обсяг виробництва товару за 1994- 1998 гг. становив 218,4 тис. т.
Середньорічний абсолютний приріст обчислюється також за формулою середньої арифметичної простий:
Щорічні абсолютні прирости змінювалися за роками від 4 до 12 тис.т (див.гр.3), а середньорічний приріст виробництва у період 1995 — 1998 гг. становив 8,5 тис. т.
Методи розрахунку середнього темпу зростання та середнього темпу приросту вимагають докладнішого розгляду. Розглянемо їх з прикладу наведених у таблиці річних показників рівня низки.
Середній рівень низки динаміки.
Ряд динаміки (або часовий ряд)- це числові значення певного статистичного показника у послідовні моменти чи періоди часу (тобто розташовані у хронологічному порядку).
Числові значення того чи іншого статистичного показника, що становить низку динаміки, називають рівнями рядуі зазвичай позначають буквою y. Перший член ряду y 1називають початковим або базисним рівнем, а останній y n - кінцевим. Моменти або періоди часу, до яких належать рівні, позначають через t.
Ряди динаміки, як правило, представляють у вигляді таблиці або графіка, причому по осі абсцис будується шкала часу t, а по осі ординат - шкала рівнів ряду y.
Середні показники низки динаміки
Кожен ряд динаміки можна розглядати як сукупність nмінливих у часі показників, які можна узагальнювати як середніх величин. Такі узагальнені (середні) показники особливо необхідні у порівнянні змін того чи іншого показника в різні періоди, у різних країнах тощо.
Узагальненою характеристикою низки динаміки може бути перш за все середній рівень ряду. Спосіб розрахунку середнього рівня залежить від того, чи моментний ряд або інтервальний (періодний).
В разі інтервальногонизки його середній рівень визначається за формулою простий середньої арифметичної величини з рівнів низки, тобто.
=
Якщо мається моментнийряд, що містить nрівнів ( y1, y2, …, yn) з рівними проміжками між датами (моментами часу), такий ряд легко перетворити на ряд середніх величин. При цьому показник (рівень) початку кожного періоду одночасно є показником на кінець попереднього періоду. Тоді середня величина показника для кожного періоду (проміжок між датами) може бути розрахована як напівсума значень упочатку і поклала край періоду, тобто. як . Кількість таких середніх буде. Як зазначалося раніше, для рядів середніх величин середній рівень розраховується за середньою арифметичною.
Отже, можна записати: .
.
Після перетворення чисельника отримуємо: ,
,
де Y1і Yn- Перший та останній рівні ряду; Yi- Проміжні рівні.
Ця середня відома у статистиці як середня хронологічнадля моментних лав. Таку назву вона отримала від слова «cronos» (час, лат.), оскільки розраховується з показників, що змінюються в часі.
У разі нерівнихпроміжків між датами середню хронологічну для моментного ряду можна розрахувати як середню арифметичну із середніх значень рівнів на кожну пару моментів, зважених за величиною відстаней (відрізків часу) між датами, тобто.  .
.
В даному випадкупередбачається, що в проміжках між датами рівні набули різних значень, і ми з двох відомих ( yiі yi+1) визначаємо середні, з яких потім вже розраховуємо загальну середню для всього періоду, що аналізується.
Якщо ж передбачається, що кожне значення yiзалишається незмінним до наступного (i+ 1)-
го моменту, тобто. відома точна дата зміни рівнів, то розрахунок можна здійснювати за формулою середньої арифметичної зваженої:
,
де - час, протягом якого рівень залишався незмінним.
Крім середнього рівня у лавах динаміки розраховуються й інші середні показники - середня зміна рівнів ряду (базисним та ланцюговим способами), середній темп зміни.
Базова середня абсолютна змінаявляє собою приватне від поділу останньої базової абсолютної зміни на кількість змін. Тобто
Ланцюгова середня абсолютна зміна рівнів ряду є часткою від поділу суми всіх ланцюгових абсолютних змін на кількість змін, тобто
По знаку середніх абсолютних змін судять про характер зміни явища у середньому: зростання, спад чи стабільність.
З правила контролю базисних та ланцюгових абсолютних змін випливає, що базисна та ланцюгова середня зміна мають бути рівними.
Поруч із середніми абсолютним зміною розраховується і середнє відносне теж базисним і ланцюговим методами.
Базисна середня відносна змінавизначається за формулою:
Ланцюгова середня відносна змінавизначається за формулою:
Природно, базисне і ланцюгове середнє відносне зміни мають бути однаковими і порівнянням їх із критеріальним значенням 1 робиться висновок про характер зміни явища в середньому: зростання, спад чи стабільність.
Відніманням 1 з базисної або ланцюгової середньої відносної зміни утворюється відповідний середній темп зміни, за знаком якого можна судити про характер зміни досліджуваного явища, відбитого даним рядом динаміки.
Сезонні коливання та індекси сезонності.
Сезонні коливання – стійкі внутрішньорічні коливання.
Основний принцип господарювання для отримання максимального ефекту – це максимізація доходів та мінімізація витрат. Вивчаючи сезонні коливання, вирішується завдання максимального рівняння в кожному рівні року.
При вивченні сезонних коливань вирішуються дві взаємозалежні завдання:
1. Виявлення специфіки розвитку явища у внутрішньорічній динаміці;
2. Вимірювання сезонних коливань з побудовою моделі сезонної хвилі;
Для вимірювання сезонних коливань зазвичай обчислюють індичок сезонності. У загальному вигляді вони визначаються ставленням вихідних рівнянь низки динаміки до теоретичних рівнянь, що виступають як база для порівняння.
Оскільки на сезонні коливання накладаються випадкові відхилення, їх усунення роблять усереднення індексів сезонності.
В цьому випадку для кожного періоду річного циклу визначаються узагальнені показники у вигляді середніх сезонних індексів:
Середні індекси сезонних коливань вільні від впливу випадкових відхилень основної тенденції розвитку.
Залежно від характеру тренду, формула середнього індексу сезонності може приймати такі види:
1.Для рядів внутрішньорічної динаміки з яскраво вираженою основною тенденцією розвитку:
2. Для рядів внутрішньорічної динаміки в якій тренд, що підвищується або знижується, відсутній, або незначний:
Де – загальне середнє;
Методи аналізу основної тенденції.
На розвиток явищ за часом впливають фактори різні за характером та силою впливу. Деякі їх носять випадковий характер, інші мають практично постійний вплив і формують у лавах динаміки певну тенденцію розвитку.
Важливим завданням статистики є виявлення серед динаміки тренду, звільненого від дії різних випадкових чинників. З цією метою ряди динаміки піддаються обробці методами укрупнення інтервалів, ковзної середньої та аналітичного вирівнювання та ін.
Метод укрупнення інтервалівзаснований на укрупненні періодів часу, до яких належать рівні динаміки, тобто. являє собою заміну даних, що стосуються дрібних часових періодів, даними по більшим періодам. Особливо ефективний, коли початкові рівні ряду належать до коротких проміжків часу. Наприклад, ряди показників, що стосуються щоденних подій, замінюються рядами, що належать до тижневих, помісячних і т.д. Це дозволить більш чітко показати «вісь розвитку явища». Середня, обчислена за укрупненими інтервалами, дозволяє виявляти напрям та характер (прискорення чи уповільнення зростання) основної тенденції розвитку.
Метод ковзної середньоїсхожий з попереднім, але в даному випадку фактичні рівні замінюються середніми рівнями, розрахованими для послідовно рухливих (ковзаючих) укрупнених інтервалів, що охоплюють mрівнів низки.
Наприклад, якщо прийняти m=3,то спочатку розраховується середня з перших трьох рівнів ряду, потім - з того ж числа рівнів, але починаючи з другого за рахунком, далі - починаючи з третього і т.д. Отже, середня хіба що «ковзає» з низки динаміки, пересуваючись однією термін. Розраховані з mчлени ковзні середні відносяться до середини (центру) кожного інтервалу.
Цей метод усуває лише випадкові коливання. Якщо ж ряд має сезонну хвилю, то вона збережеться і після згладжування методом ковзної середньої.
Аналітичне вирівнювання. З метою усунення випадкових коливань та виявлення тренду застосовується вирівнювання рівнів ряду за аналітичними формулами (або аналітичне вирівнювання). Його суть полягає у заміні емпіричних (фактичних) рівнів теоретичними, які розраховані за певним рівнянням, прийнятим за математичну модель тренда, де теоретичні рівні розглядаються як функція часу: . У цьому кожен фактичний рівень сприймається як сума двох складових: , де - систематична складова і виражена певним рівнянням, а - випадкова величина, що викликає коливання навколо тренда.
Завдання аналітичного вирівнювання зводиться до наступного:
1. Визначення на основі фактичних даних виду гіпотетичної функції, здатної найбільш адекватно відобразити тенденцію розвитку досліджуваного показника.
2. Знаходження за емпіричними даними параметрів зазначеної функції (рівняння)
3. Розрахунок за знайденим рівнянням теоретичних (вирівняних) рівнів.
Вибір тієї чи іншої функції здійснюється, зазвичай, з урахуванням графічного зображення емпіричних даних.
Як моделі служать рівняння регресії, параметри яких розраховують за способом найменших квадратів
Нижче наводяться найчастіше використовувані для вирівнювання динамічних рядів рівняння регресії із зазначенням для відображення яких саме тенденцій розвитку вони найбільше підходять.
Для знаходження параметрів наведених вище рівнянь існують спеціальні алгоритми та комп'ютерні програми. Зокрема, для знаходження параметрів рівняння прямої може бути використаний такий алгоритм:

Якщо періоди або моменти часу пронумерувати так, щоб вийшло St = 0, то наведені вище алгоритми істотно спростяться і перетворяться на

Вирівняні рівні на графіку розташуються на одній прямій, що проходить на найближчій відстані від фактичних рівнів даного динамічного ряду. Сума квадратів відхилень є відображенням впливу випадкових факторів.
З її допомогою розрахуємо середню (стандартну) помилку рівняння:

Тут n – число спостережень, а m – число параметрів у рівнянні (їх у нас два – b 1 і b 0).
Основна тенденція (тренд) показує, як впливають систематичні чинники на рівні низки динаміки, а коливання рівнів біля тренду () служить мірою впливу залишкових факторів.
Для оцінки якості використовуваної моделі динамічного ряду застосовується також критерій F Фішера. Він є відношення двох дисперсій, саме ставлення дисперсії, викликаної регресією, тобто. досліджуваним чинником, дисперсії, викликаної випадковими причинами, тобто. залишковою дисперсією:
![]()
У розгорнутому вигляді формула цього критерію може бути така:
![]()
де n – число спостережень, тобто. число рівнів ряду,
m – число параметрів у рівнянні, y – фактичний рівень ряду,
Вирівняний рівень ряду - середній рівень ряду.
Вдала, ніж інші, модель не завжди може виявитися досить задовільною. Її можна визнати такою тільки в тому випадку, коли критерій F у неї переступить відому критичну межу. Ця межа встановлюється за допомогою таблиць F-розподілу.
Сутність та класифікація індексів.
Під індексом у статистиці розуміють відносний показник, що характеризує зміну величини будь-якого явища в часі, просторі або в порівнянні з будь-яким еталоном.
Основним елементом індексного відношення є індексована величина. Під індексованою величиною розуміють значення ознаки статистичної сукупності, зміна якого є об'єктом вивчення.
За допомогою індексів вирішуються три основні завдання:
1) оцінка зміни складного явища;
2) визначення впливу окремих чинників зміну складного явища;
3) порівняння величини якогось явища з величиною минулого періоду, величиною по іншій території, а також з нормативами, планами, прогнозами.
Індекси класифікують за 3-ма ознаками:
2) за рівнем охоплення елементів сукупності;
3) за методами розрахунку загальних індексів.
За змістоміндексованих величин індекси поділяються на індекси кількісних (об'ємних) показників та індекси якісних показників. Індекси кількісних показників - індекси фізичного обсягу промислової продукції, фізичного обсягу продажів, чисельності та ін Індекси якісних показників - індекси цін, собівартості, продуктивності праці, середньої заробітної плати та ін.
За рівнем охоплення одиниць сукупності індекси поділяються на два класи: індивідуальні та загальні. Для їх характеристики введемо такі умовні позначення, прийняті на практиці застосування індексного методу:
q- кількість (обсяг) будь-якого продукту в натуральному виразі ; р- Вартість одиниці виробленої продукції; z- собівартість одиниці виробленої продукції; t- Витрати часу на виробництво одиниці продукції (трудоємність) ; w- Вироблення продукції у вартісному вираженні в одиницю часу; v- Вироблення продукції в натуральному вираженні в одиницю часу; Т- загальні витрати часу чи чисельність працівників.
Для того щоб розрізняти, до якого періоду або об'єкта відносяться індексовані величини, прийнято праворуч внизу за відповідним символом ставити підрядкові знаки. Так, наприклад, в індексах динаміки, як правило, для порівнюваних (поточних, звітних) періодів використовується підрядковий знак 1 і для періодів, з якими проводиться порівняння,
Індивідуальні індексислужать для характеристики зміни окремих елементів складного явища (наприклад-зміна обсягу випуску продукції одного виду). Вони є відносні величини динаміки, виконання зобов'язань, порівняння індексованих величин.
Індивідуальний індекс фізичного обсягу продукції визначається
З аналітичної точки зору наведені індивідуальні індекси динаміки аналогічні коефіцієнтам (темпам) зростання і характеризують зміну індексованої величини в поточному періоді в порівнянні з базисним, тобто показують, у скільки разів вона зросла (зменшилася) або скільки відсотків складає її зростання (зниження). Значення індексів виражають у коефіцієнтах чи процентах.
Загальний (зведений) індексвідбиває зміна всіх елементів складного явища.
Агрегатний індексє основною формою індексу. Агрегатним він називається тому, що його чисельник і знаменник являють собою набір «агрегат»
Середні індекси, визначення.
Крім агрегатних індексів у статистиці застосовується інша їх форма - середньозважені індекси. До їх обчислення вдаються тоді, коли інформація, що є в розпорядженні, не дозволяє розрахувати загальний агрегатний індекс. Так, якщо відсутні дані про ціни, але є інформація про вартість продукції в поточному періоді і відомі індивідуальні індекси цін за кожним товаром, то загальний індекс цін як агрегатний визначити не можна, проте можливо обчислити його як середній з індивідуальних. Так само, якщо не відомі кількості вироблених окремих видів продукції, але відомі індивідуальні індекси та вартість продукції базисного періоду, то можна визначити загальний індекс фізичного обсягу продукції як середньозважену величину.
Середній індекс -цеіндекс, обчислений як середня величина із індивідуальних індексів. Агрегатний індекс є основною формою загального індексу, тому середній індекс має бути тотожним агрегатному індексу. При обчисленні середніх індексів використовують дві форми середніх: арифметична і гармонійна.
Середній арифметичний індекс тотожний агрегатному індексу, якщо вагами індивідуальних індексів будуть складові знаменника агрегатного індексу. Тільки в цьому випадку величина індексу, розрахованого за формулою середньої арифметичної, дорівнюватиме агрегатному індексу.







